이번에 연구실에서 기업 프로젝트를 진행하던 중 의문이 생겼다. 현재는 프로젝트를 마무리한 상태이며, 자세한 내용은 다음편에 담을 듯 하다.
text embedding은 처음 하는 거라, 다방면에서 문제가 나타났다. 가장 큰 문제는 text-> vector로 변환 과정에서 메모리 용량 문제가 가장 많이 나타났던 것 같다. (각 column마다 나오는 데이터를 데이터 프레임 형식으로 excel로 저장해서)
따라서 이번에는 excel파일을 python으로 불러올때 효율적으로 처리할 수 있는 방식을 알려드릴려고 한다.
목차
- 데이터 & 프로젝트 간단 소개
- 어려움을 겪었던 부분 (용량 부족, 로드 시 오래 걸림)
- 극복하면서 알게 된 것. (excel -> csv , csv to parquent)
일단 이번 3학년 여름 방학 기업 과제는 'kisti' 기업 과제를 받았다. 그 중 우리가 해야할 task는 전처리가 되지 않는 기업에 데이터를 받아서 그 중 유의한 변수를 찾는 과제였다. 문제는 데이터의 절반 이상이 결측치이며, 어떻게 유의한 변수를 찾아야할지 막막했다.
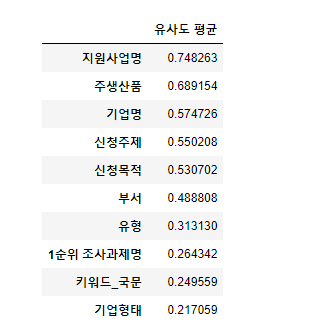
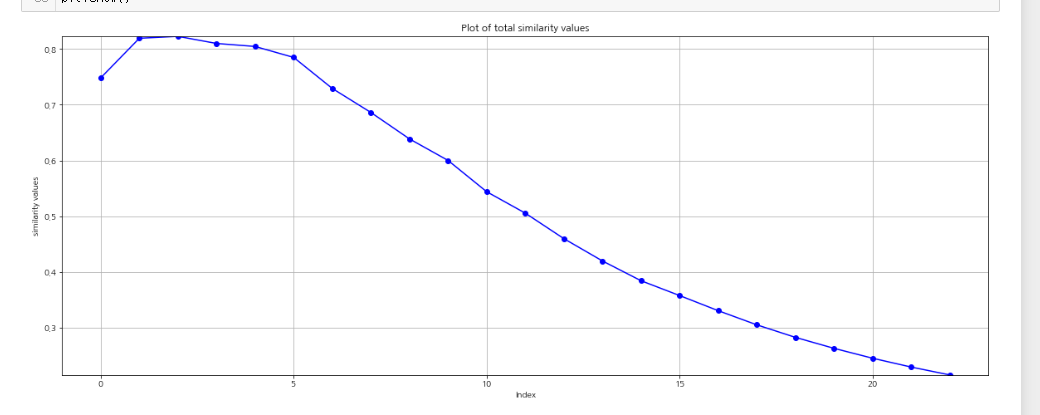
원래는 이번 방학동안 시키신 과제지만, 첫 과제이기도 하고 연구실에서 성과를 많이 내고 싶어 4일만에 다했다. 열심히 모델링을 하고, cos유사도까지 구하여 1차적으로 기업에서 유의하다고 생각하는 변수를 필터링을 완료했다.
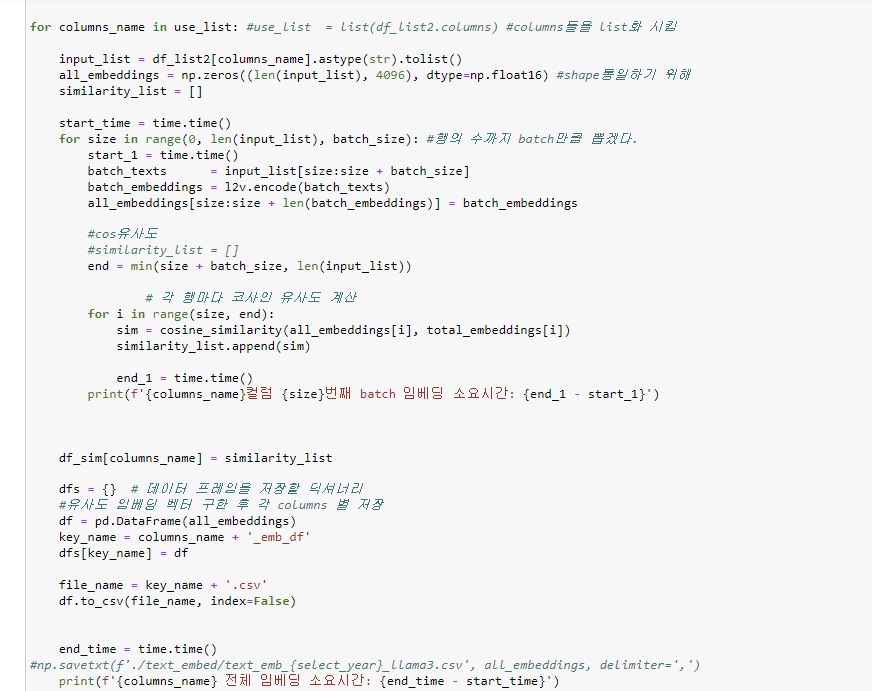
일단 사용하는 임베딩 모델이 너무 커서, 학습만 10시간 걸려서 과제를 다 했는데, 교수님이 새로운 방식으로 추가적으로 하라고 하셨다.
위 코드 보면 3중 for문을 작성한 것도 각 열별로 나오는 임베딩 벡터를 저장할 필요 없이, cos유사도를 구해서, 저장 공간을 최대한 아끼려고 했는데 다시 하려는 과제는 도출되는 모든 임베딩 벡터들을 엑셀 파일로 저장해야했다... (이럴거면 3중 for문까지 안썼지) 교수님이 원하시는 방향성에 대해 추가한 후 아무 생각 없이 'excel' 파일로 저장을 했다. (여기서 문제가 발생)
문제
- 용량 (변수 한개당 임베딩 벡터 xls파일 80mb 파일 30개)
- excel 파일 로드하여 재 사용시 로딩 시간 문제
- 로딩 시간이 너무 김. (하나 파일 부르는데 5분, 30개 전부 부르기만 하는데 150분이 걸림)
그렇다면 나는 어떻게 문제를 해결했을까?
1. 모든 excel 파일 -> csv 파일 한번에 변환
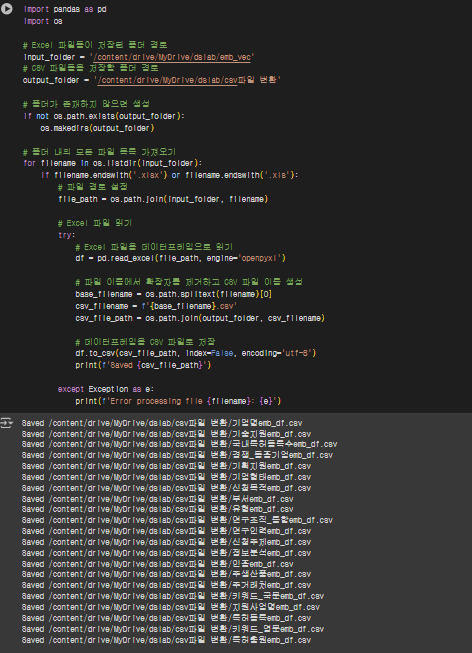
일단 가장 먼저 알아야 할 것은 데이터 프레임을 로드하고 처리하는데, 엑셀파일보다는 csv파일이 훨씬 로딩 시간이 줄어든다는 점이다. (csv 파일은 쉼표로 구분되어 저장만 하기 때문이다.)
그렇다고 변수 하나당 80mb용량이 줄어드는 것은 아니었다. 하지만 로딩 시간을 압도적으로 단축할 수 있었다.
변환을 위해 처음에 방법을 모르고 하나씩 수기로 들어가서, csv 파일로 저장하려고 했다. 하지만.. 엑셀 로딩 시간만 3분이 걸리는데 수기로 다하기에는 너무 귀찮았다.
따라서 python으로 모든 excel 파일이 담긴 폴더만 업로드하면, excel -> csv로 변환해주는 코드를 작성했다.
import pandas as pd
import os
# Excel 파일들이 저장된 폴더 경로
input_folder = '/content/drive/MyDrive/dslab/emb_vec'
# CSV 파일들을 저장할 폴더 경로
output_folder = '/content/drive/MyDrive/dslab/csv파일 변환'
# 폴더가 존재하지 않으면 생성
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 폴더 내의 모든 파일 목록 가져오기
for filename in os.listdir(input_folder):
if filename.endswith('.xlsx') or filename.endswith('.xls'):
# 파일 경로 설정
file_path = os.path.join(input_folder, filename)
# Excel 파일 읽기
try:
# Excel 파일을 데이터프레임으로 읽기
df = pd.read_excel(file_path, engine='openpyxl')
# 파일 이름에서 확장자를 제거하고 CSV 파일 이름 생성
base_filename = os.path.splitext(filename)[0]
csv_filename = f'{base_filename}.csv'
csv_file_path = os.path.join(output_folder, csv_filename)
# 데이터프레임을 CSV 파일로 저장
df.to_csv(csv_file_path, index=False, encoding='utf-8')
print(f'Saved {csv_file_path}')
except Exception as e:
print(f'Error processing file {filename}: {e}')
나는 코랩으로 사용했지만, 주피터 노트북에서 사용해도 형식만 맞으면 동일한 결과를 얻을 수 있었다.
이렇게 1차적으로 csv 파일로 변환을 하여 데이터 프레임의 로딩 속도를 높였다.
2. csv to parquent
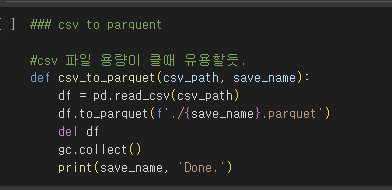
함수를 작성한 후, 개별로 저장 된 데이터 프레임을 파이썬으로 하나씩 병렬로 불러오기 위해 csv to parquent를 이용했다.
이 방식은 두 가지의 장점이 있었다.
- 메모리 용량 감소 80mb -> 7mb (용량 압도적 감소)
- 로딩 시간 줄여 줌.
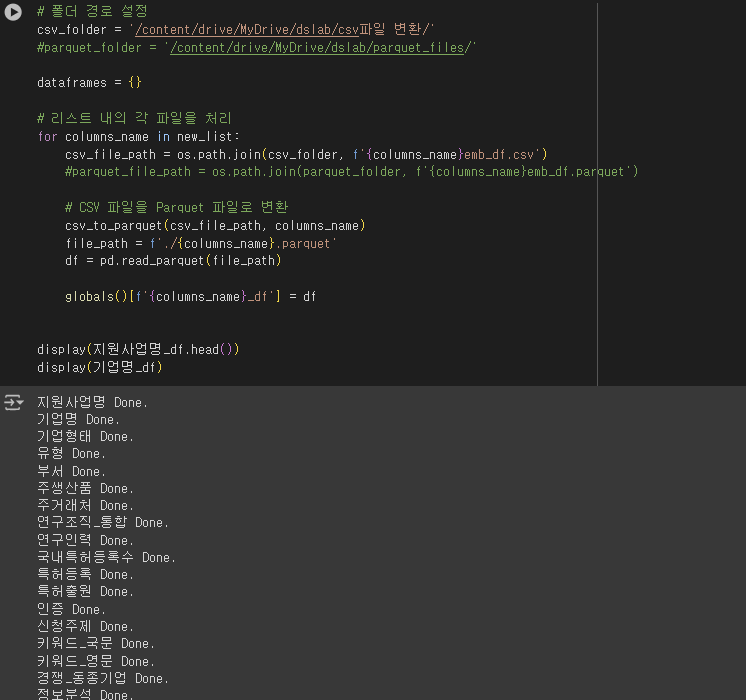
앞서 저장 된 csv 파일들이 담긴 폴더의 경로만 입력하면, 자동적으로 parquent파일로 변환과 동시에, 그 변환 된 파일을 python에 데이터 프레임으로 불러오는 코드를 작성해봤다.
### csv to parquent
#csv 파일 용량이 클때 유용할듯.
def csv_to_parquet(csv_path, save_name):
df = pd.read_csv(csv_path)
df.to_parquet(f'./{save_name}.parquet')
del df
gc.collect()
print(save_name, 'Done.')
#데이터프레임으로 부를 리스트 생성
original_list = use_list[:-2]
element_to_remove = '해외특허등록수'
# 필터링을 통해 새로운 리스트 생성
new_list = list(filter(lambda x: x != element_to_remove, original_list))
print(new_list) # 출력: ['국내특허등록수', '기타']
# 폴더 경로 설정
csv_folder = '/content/drive/MyDrive/dslab/csv파일 변환/'
#parquet_folder = '/content/drive/MyDrive/dslab/parquet_files/'
dataframes = {}
# 리스트 내의 각 파일을 처리
for columns_name in new_list:
csv_file_path = os.path.join(csv_folder, f'{columns_name}emb_df.csv')
#parquet_file_path = os.path.join(parquet_folder, f'{columns_name}emb_df.parquet')
# CSV 파일을 Parquet 파일로 변환
csv_to_parquet(csv_file_path, columns_name)
file_path = f'./{columns_name}.parquet'
df = pd.read_parquet(file_path)
globals()[f'{columns_name}_df'] = df
display(지원사업명_df.head())
display(기업명_df)
결론
데이터 프레임을 효율적으로 부르는 방식은 다른 방식들도 많겠지만, 구글링 해서 찾아본 결과 유의한 정보를 찾기 힘들었다. 따라서 나 또한, 효율적으로 로딩하는 방식에 대한 정보를 얻는데에만 2일정도 소요한 거 같다.
위의 코드들은 내가 직접 작성한 코드이기 때문에, 이 부분때문에 골치 아팠던 사람들에게 편리하면서도, 쉽게 사용할 수 있도록 작성해보았다.
실제 내가 코드를 적용하기 전, 1시간 30분 이상 로딩했어야 했을 로딩 속도가 단, 2분으로 단축 된 것을 확인할 수 있었다.
다양한 정보들이 많겠지만, 1차적으로 이 두가지를 먼저 변형해보고 해도 빠른 속도로 효율적으로 다룰 수 있을 것이라고 확신한다.
'Python' 카테고리의 다른 글
| Diffusion Model 기본: Bayesian methods (Foundation of Machine Leanrning) (0) | 2025.04.04 |
|---|