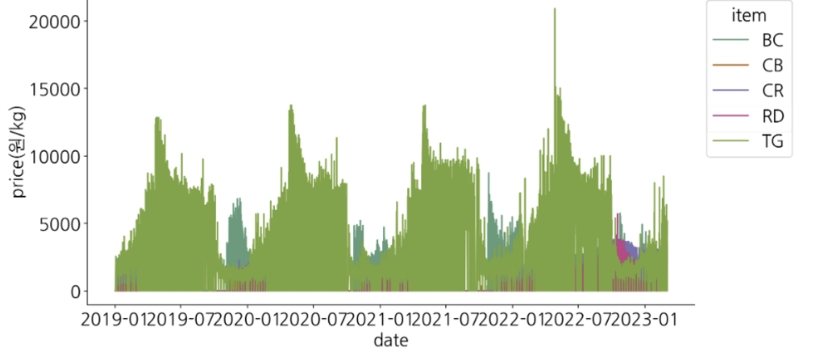
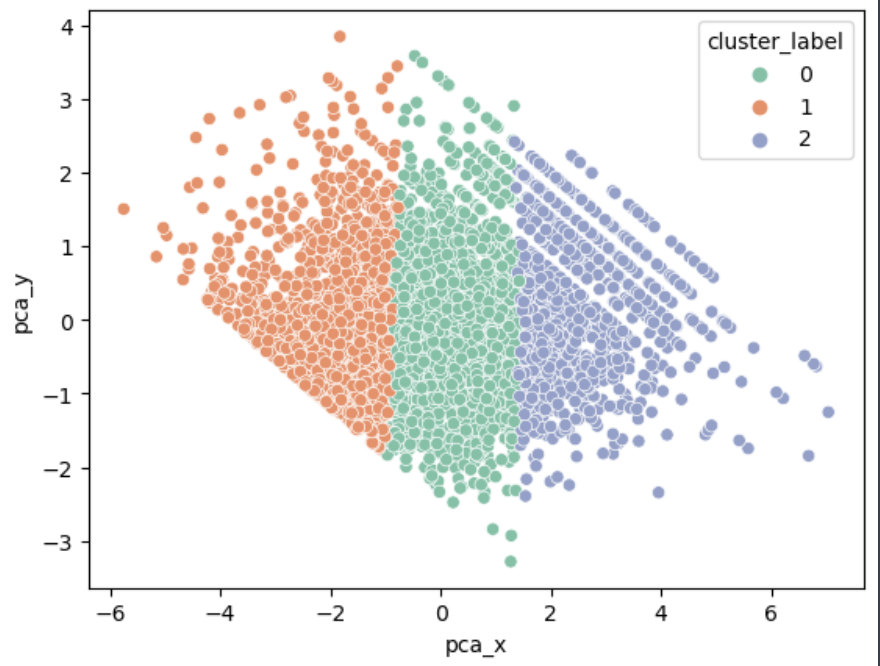
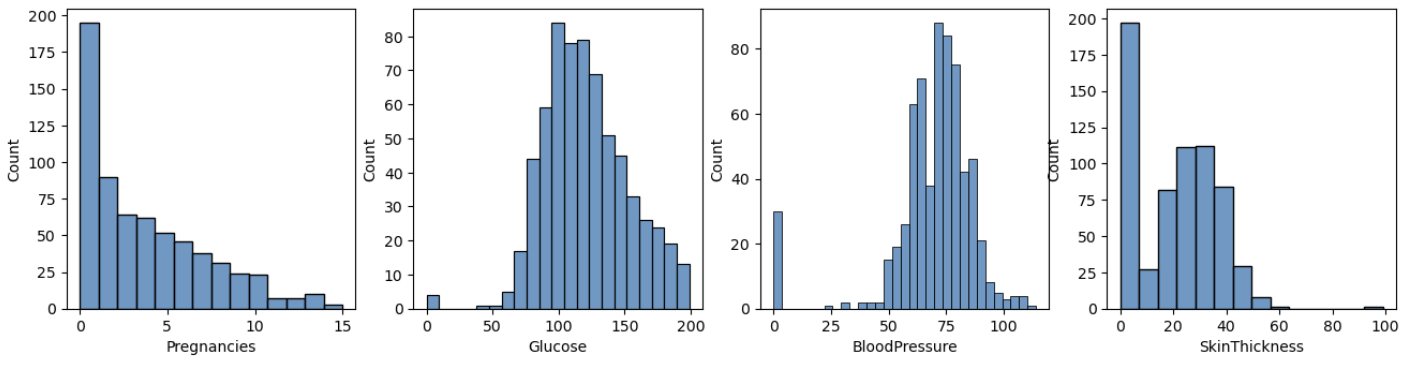
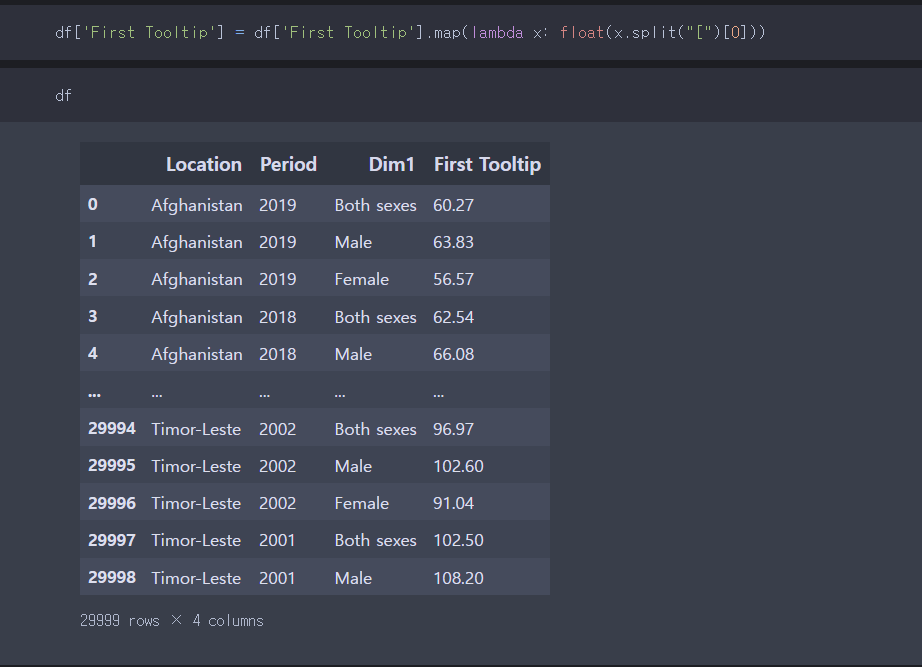
이번 보아즈 미니 플젝2에 우리는 '제주도 특산물 가격 예측 AI 경진 대회'에 나갔다. 상위 10프로 가능했을거 같긴 한데 문턱에서 끊겼다. 그래도 새로운 것을 많이 알게 되어서 이 정도면 만족이다. 성능을 업그레이드 하기 위해 우리가 집중한 방식은 3가지에만 집중했다. 전처리 피처 엔지니어링 좋은 모델 사용 이 3가지에 집중했다. 그 중 많은 내용을 다 다룰 수 없으니, 핵심 idea인 피처 엔지니어링 ,전처리에 대해 요약해 볼 예정이다. 구성 1. 문제 정의 EDA -> 어떤 문제가 있는지? 2. 문제 해결 피처 엔지니어링 전처리 3. 추가로 무엇을 하려고 했는지? 모델 앙상블 (품목 별 학습 (xgb), 회사 별 학습(xgb), 전체 학습 앙상블. (autogluon timeseires)) Met..