이번 보아즈 미니 플젝2에 우리는 '제주도 특산물 가격 예측 AI 경진 대회'에 나갔다.
상위 10프로 가능했을거 같긴 한데 문턱에서 끊겼다. 그래도 새로운 것을 많이 알게 되어서 이 정도면 만족이다.

성능을 업그레이드 하기 위해 우리가 집중한 방식은 3가지에만 집중했다.
- 전처리
- 피처 엔지니어링
- 좋은 모델 사용
이 3가지에 집중했다. 그 중 많은 내용을 다 다룰 수 없으니, 핵심 idea인 피처 엔지니어링 ,전처리에 대해 요약해 볼 예정이다.
구성
1. 문제 정의
- EDA -> 어떤 문제가 있는지?
2. 문제 해결
- 피처 엔지니어링
- 전처리
3. 추가로 무엇을 하려고 했는지?
- 모델 앙상블 (품목 별 학습 (xgb), 회사 별 학습(xgb), 전체 학습 앙상블. (autogluon timeseires))
- Meta data 활용 (무역 데이터 <-> Supply)
- price = 0이 반복되는 구간 심층 분석
| 데이터 탐색 |
item: 품목 코드
-TG : 감귤
-BC : 브로콜리
-RD : 무
-CR : 당근
-CB : 양배추
corporation : 유통 법인 코드
-법인 A부터 F 존재
location : 지역 코드
-J : 제주도 제주시
-S : 제주도 서귀포시
supply(kg) : 유통된 물량, kg 단위
price(원/kg) : 유통된 품목들의 kg 마다의 가격, 원 단위
위의 대회는 제주도 특산물 2019 ~ 2023년 2월 데이터를 갖고
2023년 3월 데이터 가격을 예측하는 것이다.
분석 전 데이터만 봤을 때?,
- 범주형 데이터가 많음 -> 선형 회귀보단 트리 계열 모델 사용
- 특산물 -> 싯가 반영이 중요
- 계절성을 학습 할 수 있는 모델 선정이 중요 (시계열 model?)
하다는 결론을 먼저 내릴 수 있다.
| 문제 정의 (EDA) |
1. 문제정의(EDA): Target 분포의 문제점
Train data: 2019.01.01 ~ 2023.03.03
Test data: 2023.03.04 ~ 2023.03.17 추정
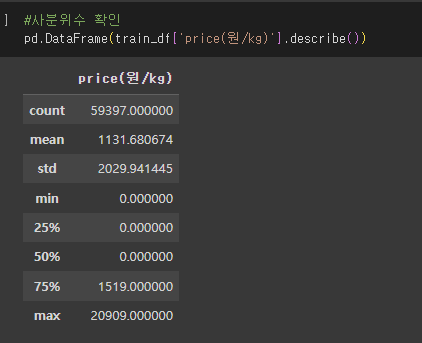
target의 문제 요약:
1. price = 0
2. 첨도가 심함 -> log 변환 (정규 분포)?
3. price = 0 적절 보간 -> 스플라인 보간 (결측치로 판단하고?)
사분위수와 plot을 찍어보면, 50프로 이상이 target값이 0인 것을 알 수 있다.
먼저 피처 엔지니어링 하기 전, 왜 price = 0 인 값들이 많은지 알아내는 것이 중요했다.
또한 supply가 0이면, price도 0인 것을 확인 할 수 있었다. (온라인 판매와 같은 건 없는 듯)
2. 문제 정의 (EDA) : supply (kg) (연속형 변수)
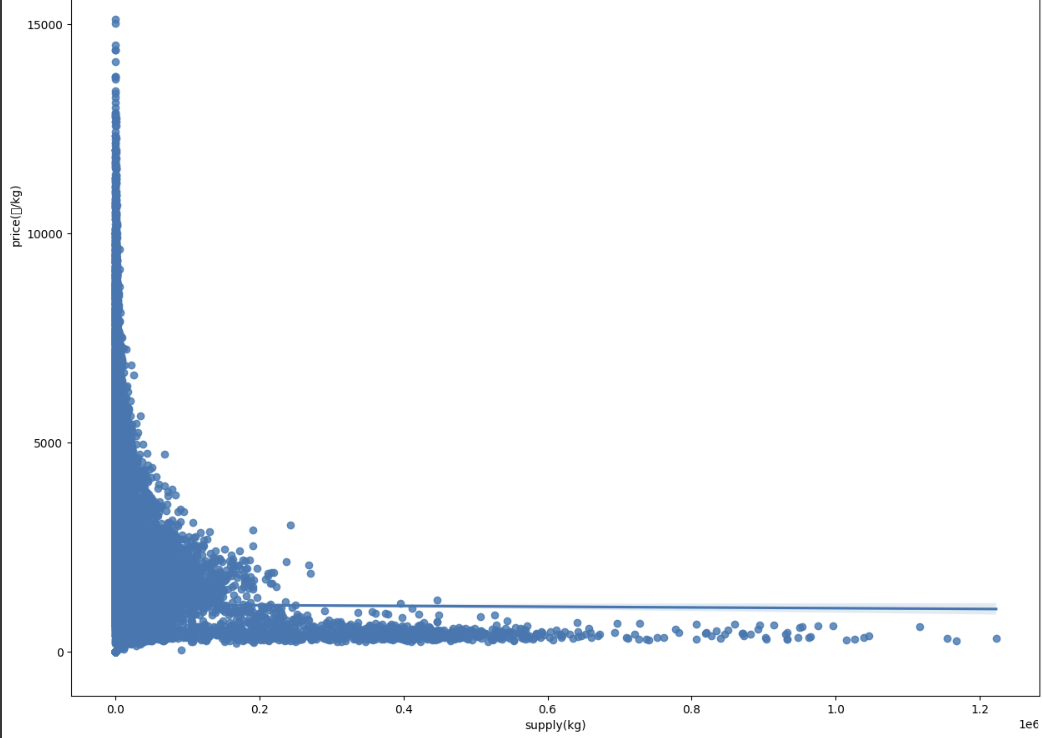

문제 요약:
1. test data에는 존재 x
2. supply = 0 -> price = 0 : 온라인 예약 판매 x
3. 0에 가까울 수록 특정 높은 가격 형성 : 시장의 원리 ?
supply :0 → price: 0 이지만,
supply가 0에 가까울 수록, 높은 price의 경향이 나타남
(전반적으로 봤을 땐 price와 supply가 큰 영향은 없는듯. 특정 피크 월마다 수요량 대비 공급량이 적어서 그러지 않을까?)
이것들 어떻게 처리해야 할까?
또한 test 데이터에는 supply열이 없는데, train에만 있는 supply열을 어떻게 잘 이용할까?
3. 문제 정의 (EDA) : 범주형 변수 (item, corporation, location)
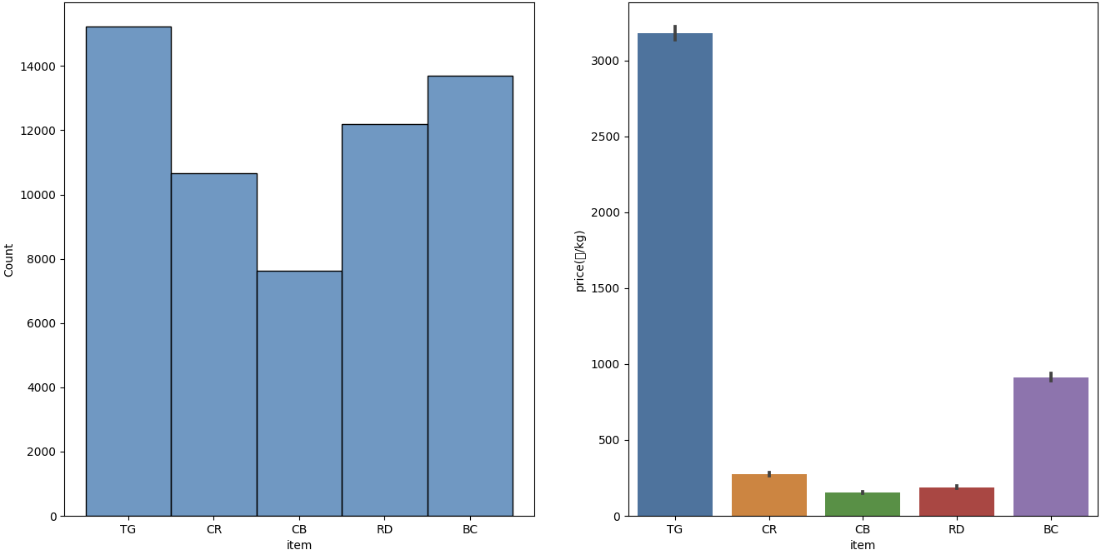
item 변수 문제 요약:
TG (감귤) 의 평균 가격이 특히 큰 것을 알 수 있음. -> 품목 별 분리해서 학습 ? or 이상치 처리시 품목 별 처리 ?
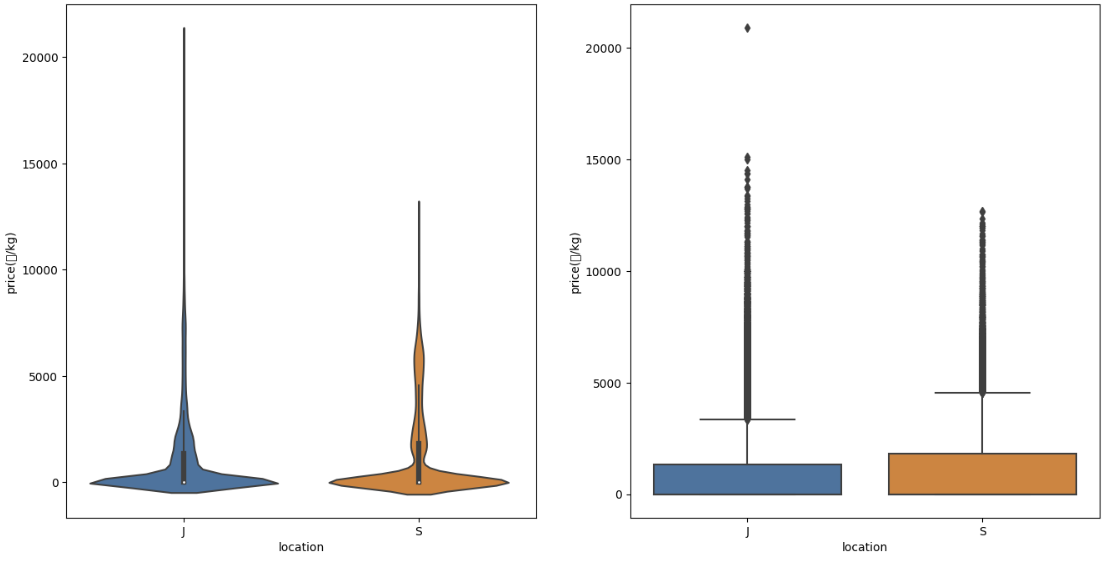
제주도의 특산물일 수록 극단적인 가격 차이 나타남, but 평균 가격 형성은 서귀포가 더 높음.
-> 별로 의미 없을 듯? 이용하는 것은.
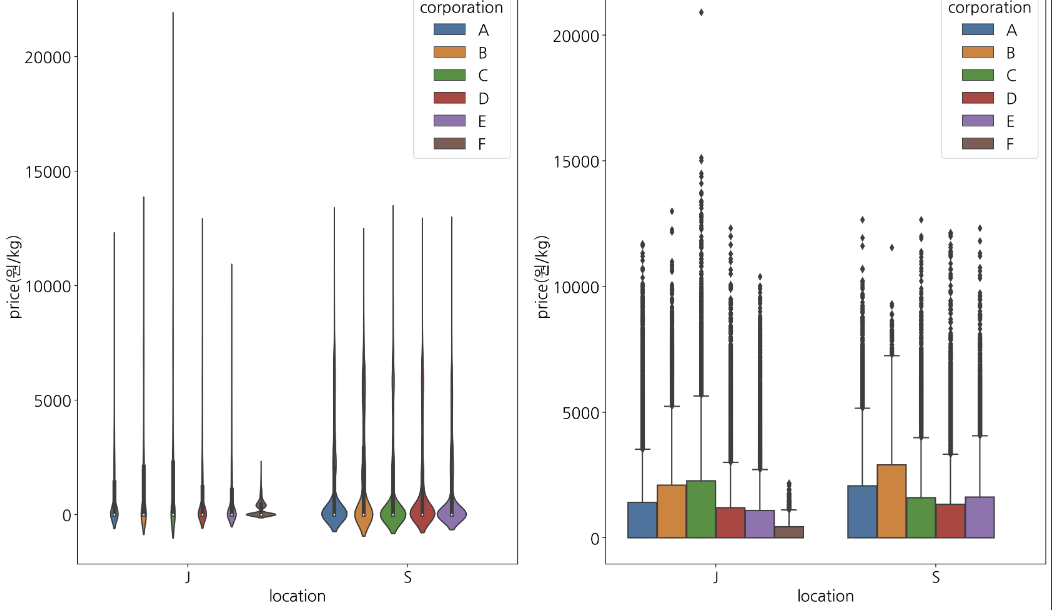
같은 회사 (corporation) 이어도 제주시와 서귀포시 두 곳에 존재한다는 것을 알 수 있음.
4. 주기성 분석
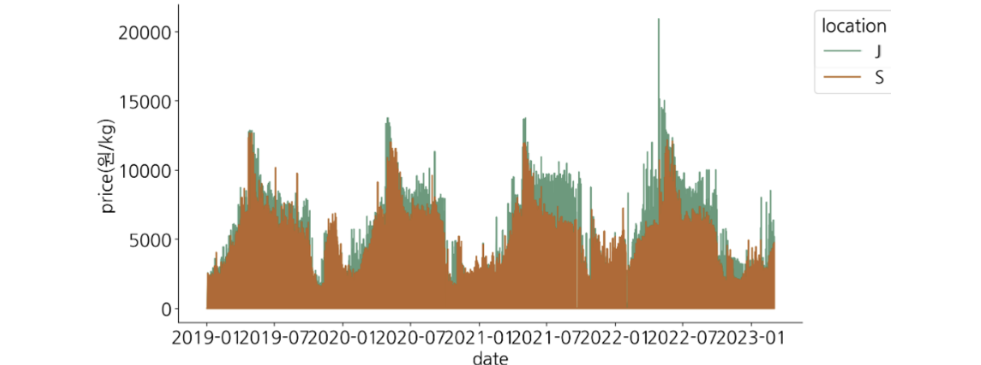
- location별 가격 변동 주기
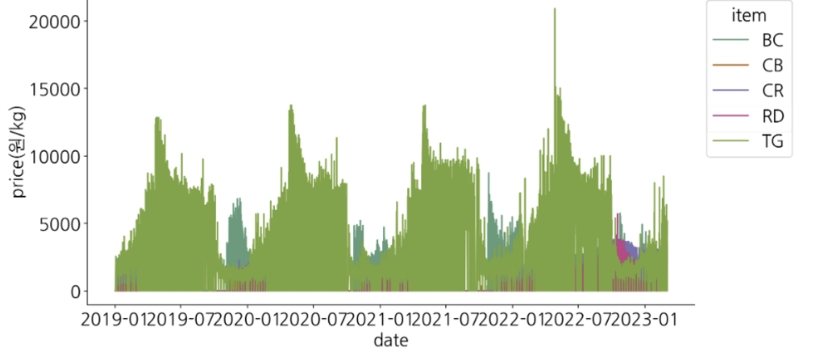
- item별 가격 변동 주기
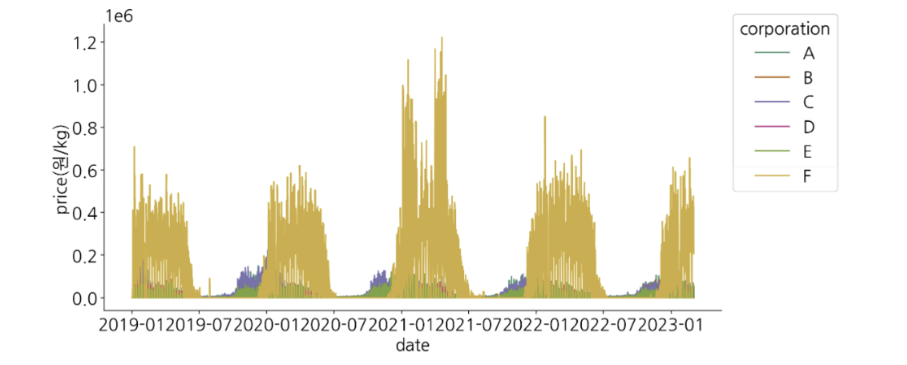
- corporation별 가격 변동 주기
주기성 변수 문제 요약:
1. 주기성 (범주형 변수 별 특정 주기)
2. 특정 이상치의 원인 ?
-> 모두 계절성이 돋보임 (계절성을 학습 할 수 있도록 피처 엔지니어링 방식, 전처리)
문제정의 종합 요약:

위의 말한 문제점들을 하나씩 요약하면 3가지 결론을 낼 수 있다.
위의 총 요약된 3가지를 해결하는 방식으로 진행 했다.
밑에 문제 해결 부분을 볼 때도 순번 위주로 집중하여 보면 된다.
| 문제 해결 |
1. 첨도가 심한 target ->log 변환
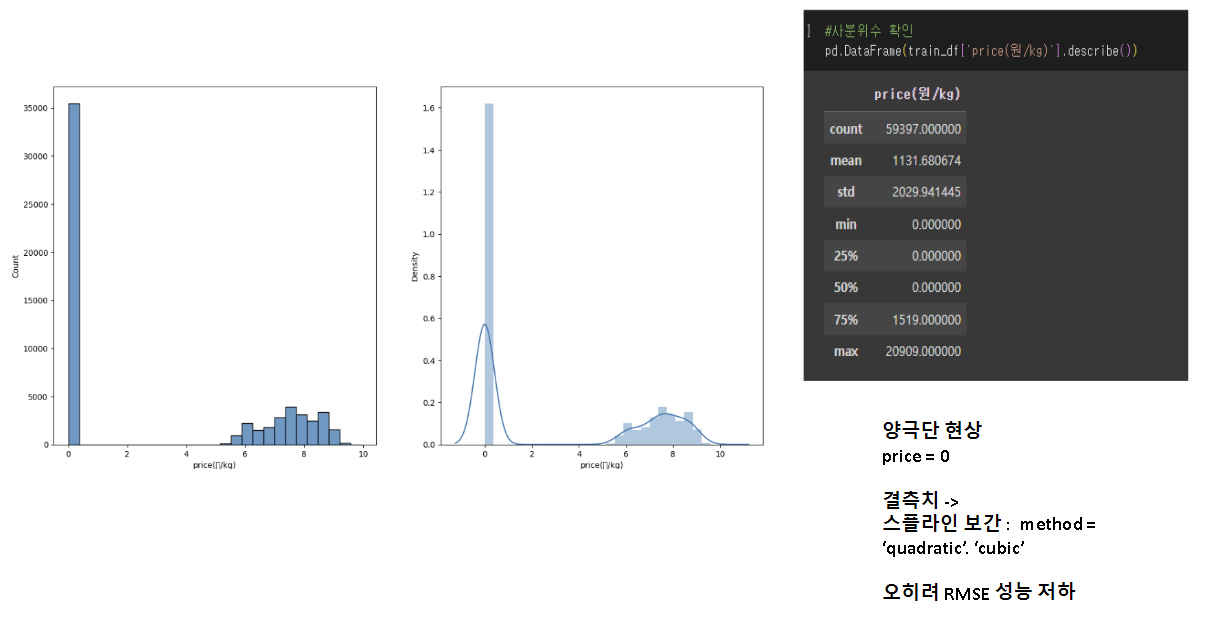
기존 첨도가 높아 log 변환을 수행했다.
정규 분포로 만들어 보편 적인 예측 결과를 만들어 낼 수 있기 때문이다.
또한 price = 0인 값의 비율이 50프로가 넘어 이것을, 단순 결측치로 보고 시계열 전처리 방식인 스플라인 보간을 해봤다.
하지만, 결과적으로는 평가 지표인 RMSE의 성능 저하로 이어졌다.
price = 0인 값들의 이유가 있기 때문에, 이것들을 단순 결측치로 봐서는 안될거 같다.
2. 계절성 피처 엔지니어링 -> PolynomialFeatures
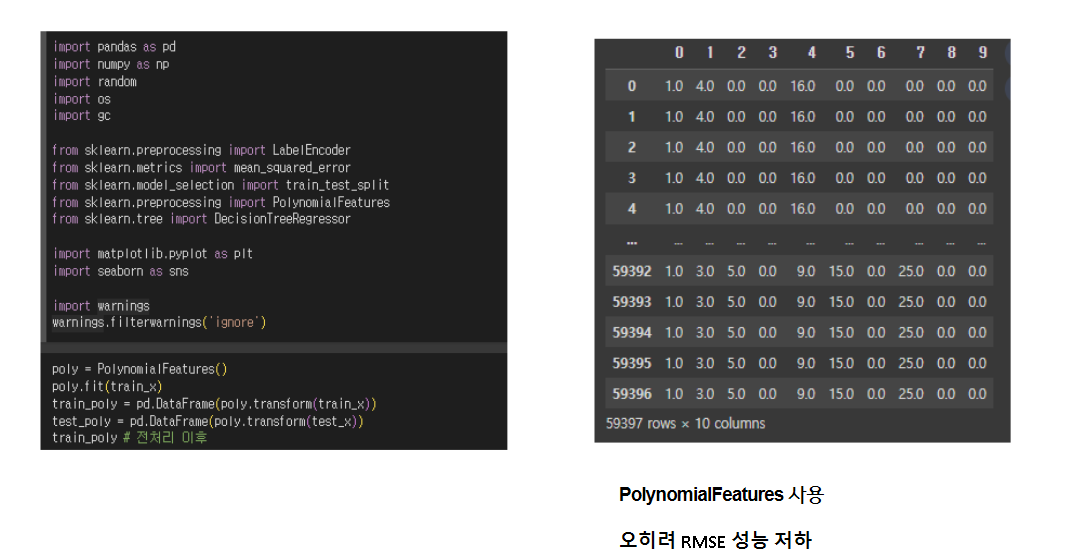
앞에 train data만 봐도 알 수 있듯, 학습에 사용되는 피처는 대부분이 범주형 변수이며 심지어 피처의 수도 매우 작다.
당시 나는 계절성 피처 엔지니어링 방식을 몰랐기 때문에, 가능한 조합의 피처들을 만들어주는 polynomialFeatures를 사용했다.
-> 오히려 성능 저하
2. 계절성 피처 엔지니어링 -> 공휴일 변수 추가
prcie = 0 인 부분이 너무 많아 공휴일 변수를 추가해줬다. (패키지 이용)
보통 공휴일에 영업을 안하니, (시간 데이터가 공휴일이면, 영업을 안하는 날 price = 0 -> 성능향상 기대)
Train data: 2019.01.01 ~ 2023.03.03
Test data: 2023.03.04 ~ 2023.03.17 추정
데이터 내부를 살펴보면 2023년의 전체 시간 데이터는 없다.
함수로 만들어 2023년 일부까지라도 적용하려고 했지만, 오류가 발생.
따라서 2023년의 공휴일 적용은 커스텀 처리했다.
! pip install holidays
!pip install pytimekr
from pytimekr import pytimekr
import holidays
import pandas as pd
import datetime
#2019 ~ 2022 공휴일 데이터 처리
def add_weekday(df):
df['date'] = pd.to_datetime(df['timestamp'])
df['weekcode'] = df['date'].dt.weekday
year_min = df['date'].dt.date.unique().min().year
year_max = df['date'].dt.date.unique().max().year
kor_holidays = list(holidays.KOR(years=range(year_min, year_max)).keys()) # 2019~2022년 공휴일을 포함하도록 수정
idx_kor_holidays = pd.to_datetime(kor_holidays) #2023년 공휴일은 수기 수정
# 인덱스에 공휴일 날짜를 추가
df_temp = df.set_index('date')
df_temp['is_holiday'] = 0 # 새로운 열을 만들고 초기값을 0으로 설정
df_temp.loc[idx_kor_holidays, 'is_holiday'] = 1 # 공휴일인 날은 1로 설정
df_temp.reset_index(inplace=True)
df['weekcode'] = df_temp['is_holiday'] # 'weekcode' 열을 'is_holiday' 열로 대체
return df
test 2023년의 데이터를 예측하는 것이니, 예측의 정확도를 올리기 위해 대체 공휴일등 빠진 공휴일까지 함께 커스텀 처리 했다.
#2023 수기 처리
kr_holidays_2023 = pytimekr.holidays(year=2023)
#대체 공휴일, 빠진 공휴일 커스텀 처리 2023
kr_holidays_2023.append(datetime.date(2023, 5, 29))
kr_holidays_2023.append(datetime.date(2023, 1, 24))
#2022년까지의 공휴일 정보 load
train_df = add_weekday(train_df)
test_df = add_weekday(test_df)
#2023년 수기처리 함
def add_weekday_2023(df, kr_holidays_2023):
# kr_holidays_2023에 포함된 날짜의 'weekcode'를 1로 변경
df.loc[df['date'].isin(kr_holidays_2023), 'weekcode'] = 1
return dftrain_df = add_weekday_2023(train_df, kr_holidays_2023)
test_df = add_weekday_2023(test_df, kr_holidays_2023)
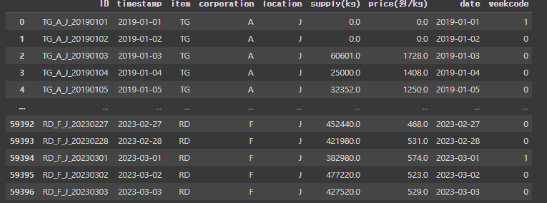
weekcode라는 열에 공휴일이면 1 아니면 0이 들어간 것을 확인 할 수 있음.
'Python > 코딩 실습' 카테고리의 다른 글
| Samsung AI Challenge: Black-box Optimization (1) | 2025.04.07 |
|---|---|
| 결측치 leakage 없이 트리 예측 모델로 보간 (MICE 보간 사용 X) (1) | 2023.10.30 |
| 데이콘 기본 ML 대회에서 알게 된 것들 (왕초보편) (2) | 2023.10.06 |
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |