얼마 전, 혼자 추석 동안 열린 데이콘 추석 맞이 추석 선물 수요량 예측 AI 경진 대회에 참여했다.
처음하는 대회여서 진짜 무엇을 해야할지 몰랐고, 공부하면서 ML에도 다양한 방식들이 많았다는 것들을 깨달았다.

추석때는 생각도 안하고 놀다가 마지막에 2일 정도 열심히 했는데, 시간 부족도 있었지만 기본적으로 내 실력이 너무 부족했다.. 총 351명 참여 중 PRIVATE 65등을 했다.
학습도 짧은 시간만 했고, 전처리도, 데이터에 대한 이해도도, 떨어져서 당연한 결과고 오히려 운이 좋았다고 생각한다.
다음 번 대회에는 조금 더 준비하여 상위 10퍼센트 찍으려고 할 것이다.
- 1. 내가 집중한 Point
- 2. 대회를 준비하면서 알게된 것
- 3. 대회 참여 중 알게된 유용 코드나 모델 (CSV 파일 처리, AUTO ML, 앙상블)
- 3. 느낀점
으로 서술하겠다.
| 집중 Point (어떻게 잘하는 사람 중 경쟁력을 가져갈까?) |
3가지를 생각했다.
1. 버릴 것은 과감하게 버린다. (피처 엔지니어링).
2. 관련 regression kaggle 커널이나 데이콘 커널 분석.
3. 좋은 모델 사용.
첫 대회이고 관련 지식이 부족하여, 잘하는 사람들이 스스로 짜는 코드를 무조건 이기지 못할 것이라고 생각했다.
그리고 시간도 2일이라는 짧은 시간을 갖고 준비했기 때문에, 각 피처 변수들을 통합하거나 새로운 파생 변수를 만드는 것 보다. 어느정도 기본 전처리만 완성한 후 좋은 모델과 좋은 방식으로 승부를 보려고 했던 거 같다.

또한 일단 내가 기본 지식이 부족하니 대회에서 잘하시는 분들이나 작성한 regression 관련 코드들을 분석하고 중 유용할 거 같은 코드는 접목시키려고 했던 것 같다. 그리고 이 방법들이 실제로 성능을 향상시키는데 너무 큰 도움이 되었다.
(역시 좋은 모델을 사용하는 것이 최고 ... !)
| 대회를 준비하며 알게 된 것들 |
첨도가 심한 경우 로그 변환
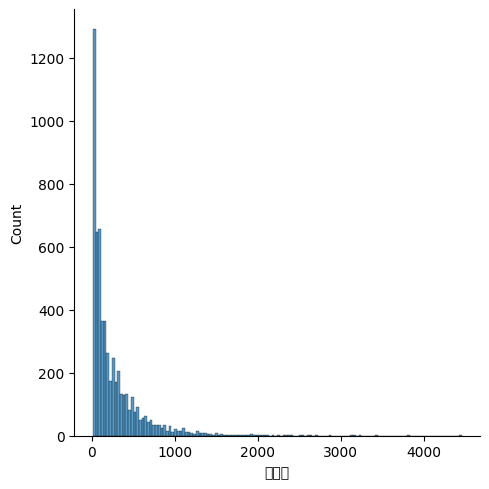

'첨도가 심하면 로그변환을 해라' . 알고 있었다. 근데 이것으로 성능이 많이 향상 되었다. 사실 대단한 변환을 한 것도 아닌데, log변환 하나로 RMSE 판별시 성능이 기본 6이상 향상 되었다.
OUTLINE 제거.. 성능 저하 발생


이상치가 너무 많다. 전체가 데이터의 개수가 5872개의 데이터 셋이 있는데, 수요량의 MAX값이 4455인 값인데 75퍼센트의 데이터 셋이 수요량 350 안에 있었다.

ADsP에서 배운대로 Q3 + 1.5*IQR을 구하고 (outline 기준 수요량: 794였음), 이 기준을 바탕으로 이상치 제거를 해보고 성능을 검사해봤다.
성능은 반토막이 나버렸다.. 추후에 진짜 이상치가 너무 심한 3가지 데이터만 삭제하고 나머지는 그대로 진행했다.
그래도 성능 하락, 극단 이상치가 제거된다고 무조건 성능이 향상 되는 것은 아닌듯.
Feature importance의 양면성

범주형 데이터 셋이 많아 선형 회귀 모델 보단, 트리 모델이 성능이 좋을 거 같아서, xgb regressor를 사용했다.
(matplotlib이나 seaborn 사용시 한글 폰트 불러야 하는데 귀찮아서 안부름..)
일단 기본 코드로 학습을 한 후 feature importance를 뽑아봤는데.. 한 변수에만 유독 과도하게 큰 가중치를 남겨두는 것을 확인할 수 있었다.
당연히 변수를 제거하여 학습할 때 이 변수는 어떻게든 남겼는데.. 실제로 한번 중요성이 높은 변수를 제거하고 학습을 해보니, 성능이 올라갈때도 있었다. 한 곳에 너무 많은 가중치를 두어서 다른 곳에 영향을 줄여서 그런거 같긴 하다. 앞으로 판단을 할때도 feature importance만 믿고 판단을 하면 안될거 같다.
(그래도 변수 삭제 보단, 파라미터 수정하면서 점차 줄여가는게 베스트이긴 했다.)
| 유용한 코드나 모델 |
CSV 파일 메모리 용량 줄이기

데이터가 크진 않았지만, 유용할 거 같아서 갖고 왔다. 실제로 다른 데이터셋에서 40,000장에 데이터를 로드하는데 걸리는 시간이 확실히 단축되었던 것을 볼 수 있었다. 이번 대회에서도 조금 더 가벼운 메모리를 사용하면 시간이 단축되지 않을까 싶어서 사용했다.
AUTO ML (pycaret)

캐글이나 데이콘 커널 분석시, pycaret으로 최적 모델 찾고 학습하는 분이 계셔서 나도 한번 써봤다.

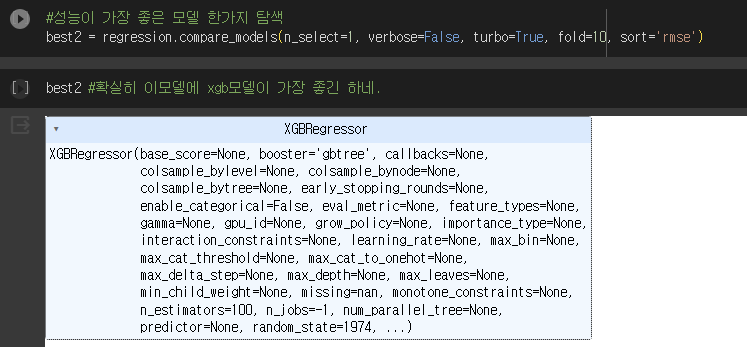
오.. 신기해 역시 xgb regressor가 추천 모델로 나왔다.. cat boost나 ExtraTreesRegressor도 써보고 싶었는데, xgb regressor를 기준으로 학습을 했다.
AUTO ML (autogluon)



파라미터 설명
label : target값
eval_metric : 평가 지표
time_limit : 학습 제한 시간이 모델을 제출 6시간 전에 알아서.. 학습 limit을 4시간만 학습하도록 했다. 보니까 GPU 환경에서도 쓸 수 있을 거 같긴한데, 내 컴퓨터에 GPU가 없고 Colab에서 제공하는 GPU를 사용하여 학습 중 런타임이 끊길거 같았다.
학습 시켜놓고 자고 일어나서 리더보드 점수를 확인해봤는데, 내가 Optuna나 random search로 직접 하이퍼 파라미터 튜닝한 것보다 높은 점수를 얻었다. 앞으로 무조건 유용하게 쓸 거 같다.
하이퍼 파라미터 튜닝(grid search -> random search -> optuna 사용)

이전 grid search 방식으로 하이퍼 파라미터 튜닝을 하는 법은 알았는데, 엄두가 안났다. (속도가 너무 오래걸림..)
그리고 grid search가 격자 형태로 하나씩 다 찍어보는 방법이니 그것보다는 스스로 최적화 하면서 최적 파라미터를 도출해주는 hyper opt를 사용할까 고민했는데 사용법이 헷갈리는 부분이 많았다.
-> 첫번째 대안 random search

grid search는 속도면에서 너무 느리고, 대회에서 hyper opt 방식을 사용하는 분들이 거의 없었기 때문에 random search를 사용했다.

하나씩 넣어보면서 성능이 좋아졌다. 그래도 당시에 큰 성능 향상은 없었음.
-> 두번째 대안 AUTO ML optuna 사용
더 큰 성능 향상을 위해 많은 대회 참여자 분들이 사용하는 optuna 모델을 사용했다.
빠르게 튜닝이 가능하고, 직관적인 이해가 가능해서 더 유용할 거 같았기 때문이다.


이미 '테디 노트' 분께서 올려주신 라이브러리가 있어서, 그것을 적극 활용했다 ..!
캐글/데이콘 경진대회 Baseline을 잡기 위한 optuna + [xgboost, lightgbm, catboost] 패키지 소개
캐글/데이콘 경진대회 Baseline을 잡기 위한 optuna + [xgboost, lightgbm, catboost] 패키지 소개드리도록 하겠습니다.
teddylee777.github.io
참고 해보세여

이 분께서 기본으로 작성하신 모델의 범위가 있다. 파라미터 범위를 확인하고, 데이터 셋에 맞게 범위를 약간 수정했다.



어느정도 최적 파라미터 찾았다. 리더 보드에 올리고 점수를 확인하니, random search보다 성능 향상이 있었다.
마지막 예측값 앙상블 (autogluon + random search + optuna)

마지막은 앙상블 했다. 앙상블이라고 해서, 보팅 부스팅 배깅 모델처럼 어려운 작업일 줄 알았는데, 각각 예측값의 일정 비율을 곱하고 더하는 작업이었다.
높은 점수를 주는 값은 높은 비율로 곱해줬다.
| 마무리 하며 |
1. 피처 엔지니어링을 조금 더 알아봐야겠다. 좋은 전처리가 있어야 좋은 성능을 기록하기 때문이다.
2. 학습 시간이 짧고 모델이 조금 얕았는데, 좋은 모델로 오랜 학습을 하는 방식을 적용해야겠다.
3. 과적합 주의, xgb모델만 사용하니까 앙상블시 분명 과적합이 있었을 것이다. 앞으로 모델을 조금더 유연하게 하는 법 익혀야겠다.
'Python > 코딩 실습' 카테고리의 다른 글
| 시계열은 처음이라 (제주도 특산물 가격 예측 AI 경진 대회) (3) | 2023.11.21 |
|---|---|
| 결측치 leakage 없이 트리 예측 모델로 보간 (MICE 보간 사용 X) (1) | 2023.10.30 |
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |
| [1일 1 캐글] Default of Credit Card Clients Dataset, PCA 이용 (0) | 2023.05.31 |