
정형 데이터 마이닝 방법이고 분류 방법을 이용한다.

데이터를 확인해보자.
Pregnancies : 임신횟수
Glucose : 포도당 농도
BloodPressure : 혈압
SkinThickness : 피부두께
Insulin : 인슐린
BMI : 체질량지수
DiabetesPedigreeFunction : 당뇨병 혈통 기능
Age : 나이
Outcome : 당뇨병 여부(0: 발병되지 않음, 1: 발병)
df.info()를 확인한 결과 결측값이 없음을 알았다.

| EDA 탐색적 데이터 분석(시각화) |

먼저 ID칼람은 index와 비슷한 값을 가지고 의미 없으니 삭제한다.

1. df.columns을 이용하여 데이터 프레임의 칼람들만 뽑는다.
2. 이후 리스트로 만들어 나중에 시각화를 위해 for문을 사용할때 수월하게 만든다.
3. outcome삭제 한다. 나중에 시각화시 outcome을 기준으로 바이올린 플랏을 만들것인데 연속형 값에 대한 빈도를 확인할때, outcome이 두번 들어갈 필요가 없기 때문이다.

[Description(설명) : 시각화 코드를 이해하기 위한 설명 이미 아시는 분들은 넘어가셔도 된다.]
데이터를 어느정도 다듬었으면, 먼저 히스토그램이나 바이올린 플랏으로 각 데이터의 연속형 값의 빈도를 알아봐야한다.

df.head(3)로 상위 3개 칼람만 추출했다. 숫자를 보면 outcome을 제외한 나머지 칼람들이 연속형 칼람이다. 어떤 생각이 먼저 드는가?
나는 outcome을 기준으로 각 칼람들의 빈도를 추출하고 비교해야겠다. 생각이 먼저든다. 분포를 확인하고 각 칼람별로 어떤 수치일때 '당뇨병에 더 걸리기 쉬운지'를 파악하기 쉽다.
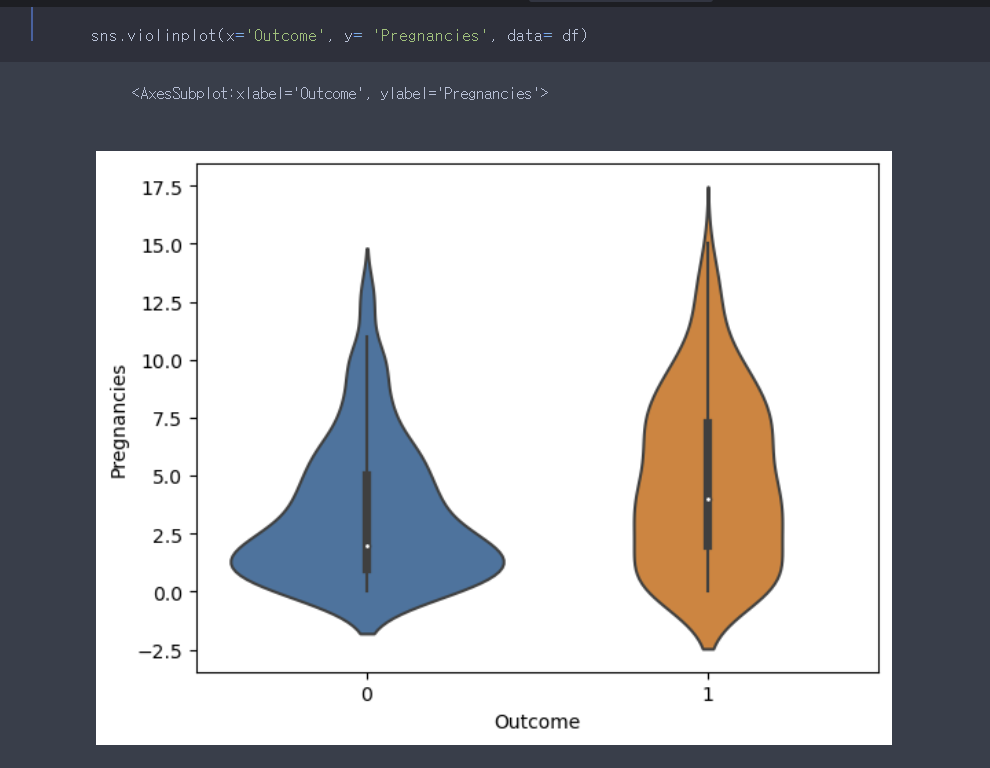
예시로 'outcome'별 ' , 'pregnancies'의 빈도를 한눈에 파악하기 쉽게 먼저, 바이올린 플랏으로 작성했다. 이러면 히스토그램 사용했을때 보다 장점이
1. 각각의 빈도수만 보여주는 것이 아니라, outcome이라는 이산형 변수를 기준으로 나눠서 pregnancies의 분포를 보여주니, 한눈에 파악하기 더 쉽다.
2. 쉽게 비교하기가 쉽다.
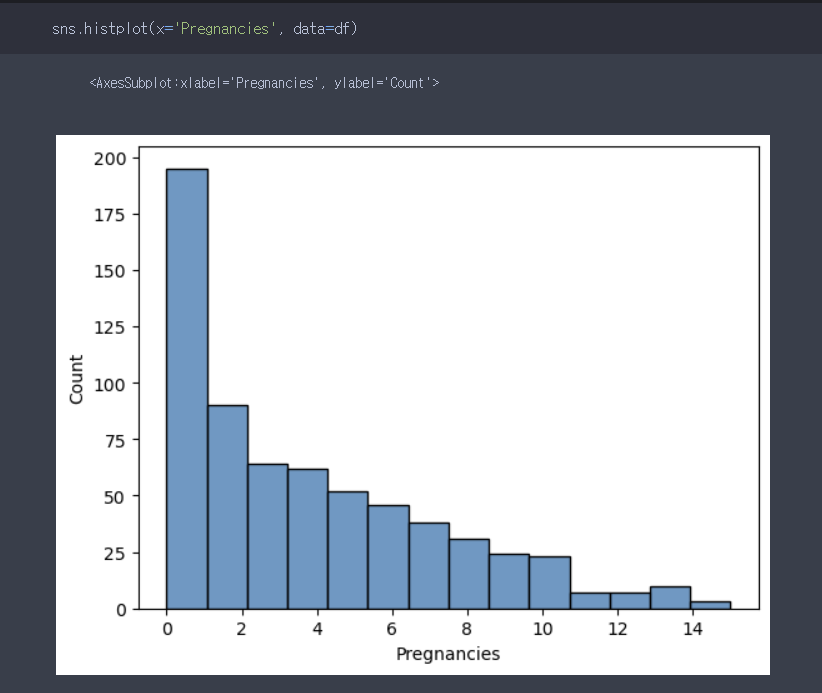
이렇게 histplot으로 히스토그램을 추출하게 되면 outcome(당뇨병 o, x)별 pregnancies의 분포 파악이 힘들다.
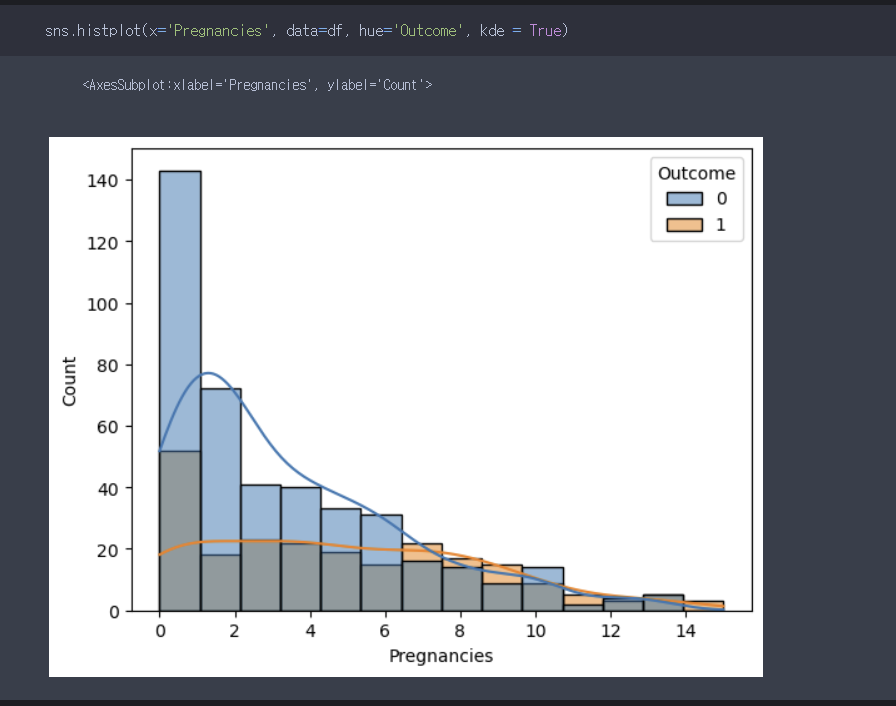
물론 hue 파라미터를 사용해서, 데이터를 그룹으로 만들고 시각화 시킬수 있다. 나는 약간 기존의 히스토그램을 쪼개는 느낌을 받아서, 쉽게 앞서 보이는 히스토그램을 outcome별로 세부적으로 쪼갠다는 느낌으로 이해했다. 하지만, 여러개의 막대가 겹쳐 한눈에 파악하기 힘들다.
다시 코드로 돌아와서, 앞서 만든 바이올린 플랏을 8개 만들어야한다.(outcome제외)
지금처럼 개별적으로 하나씩 작성하면, 번거러움도 많고 비교가 쉽지 않다. 따라서 하나의 코드로 8개의 바이올린 플랏을 넣는 방법을 쓴다.
plt.subplots()으로 8개로 나누고, for문을 이용하여 만들것이다.
for문으로 각 칼람들을 루프를 돌려 작성할것이다. 먼저 이해하기 쉽게 코드부터 보자.
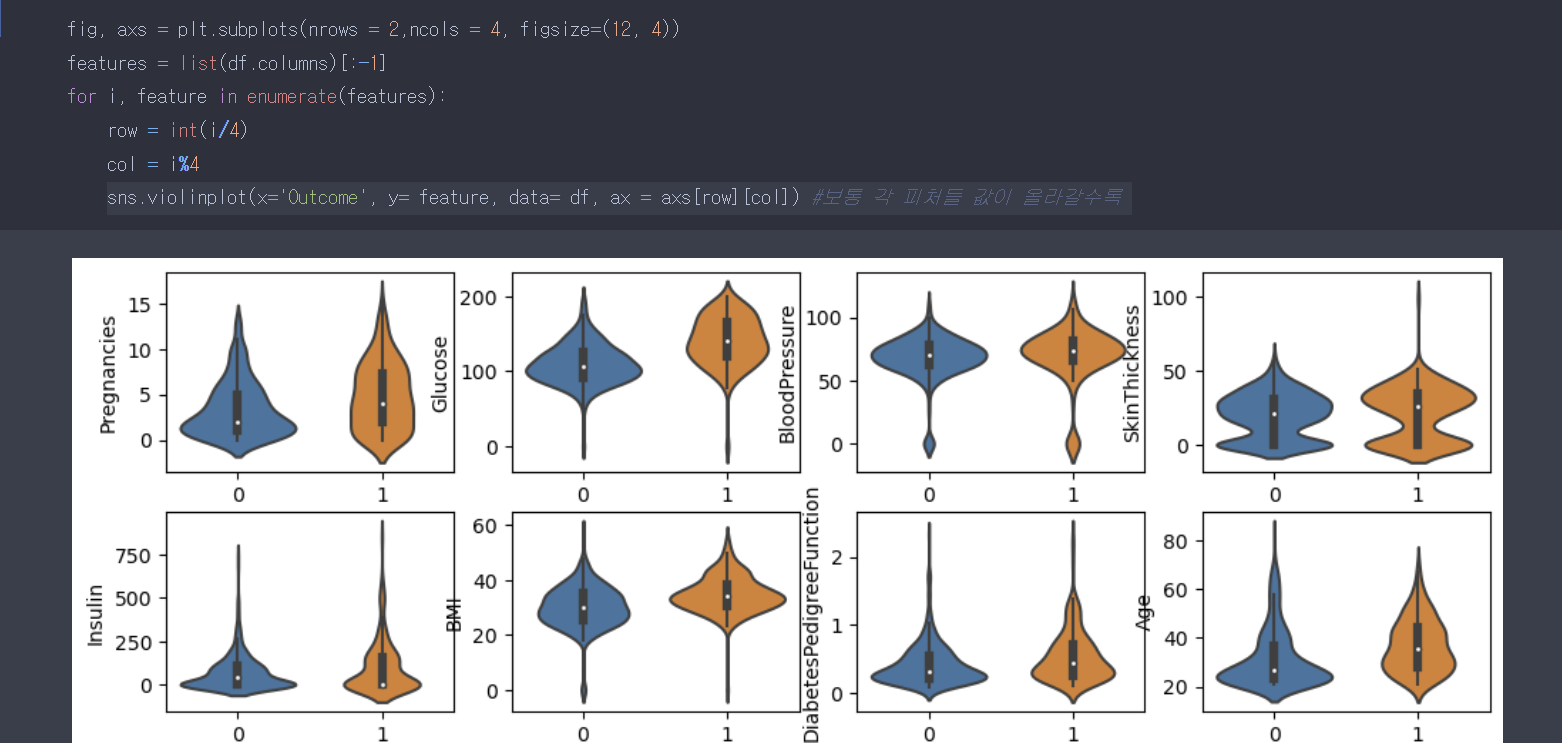
코드만 따로 봐보자.

plt.subplots을 이용하여 행이 2, 칼람이 4인 작은 플랏들의 tool을 만든다.
for문과 enumerate를 이용하여, 각각 enumeraite돌렸을때 각 칼람별 해당하는 인덱스가 row와 col계산하는 방식으로 수행되어, ax파라미터로 들어가게 된다. ax파라미터는 각 위치에 해당하는 그래프를 만들 수 있도록 도와준다.
##더욱 세부적으로 알고 싶으면,
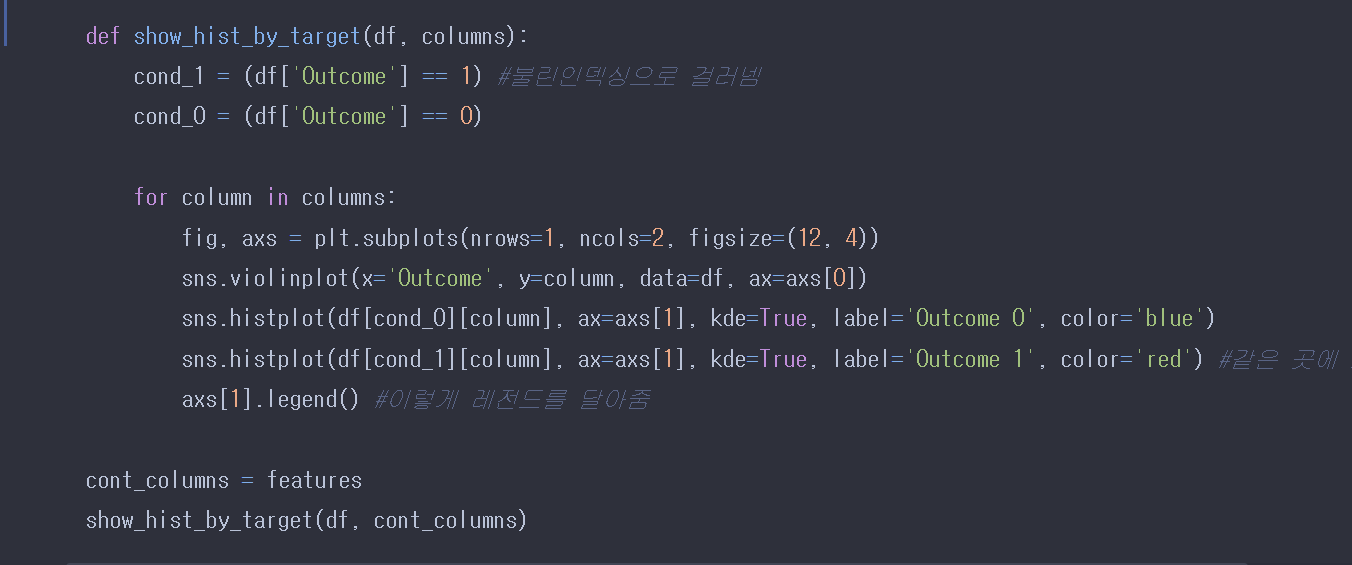
코드를 이용해서 바이올린 플랏과 함께 보조적으로 히스토그램 분포를 본다. 더욱 자세하게 알 수 있다. 코드를 살펴보면 그냥 결과가 0인지, 1인지를 팬시인덱싱하여, 만드는 코드이다.
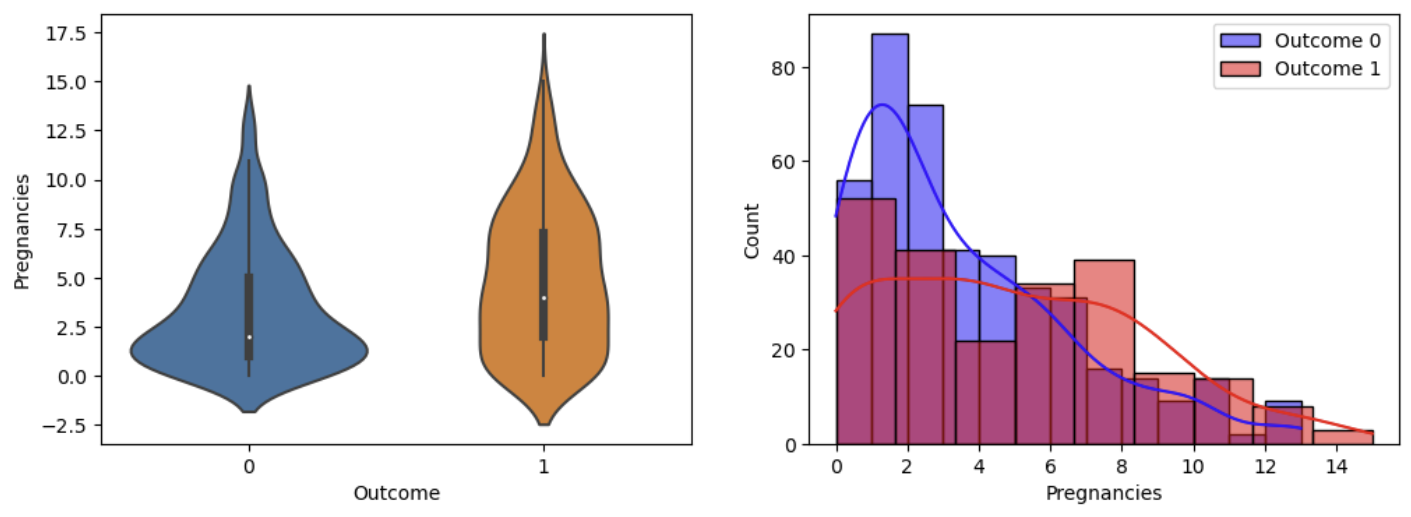
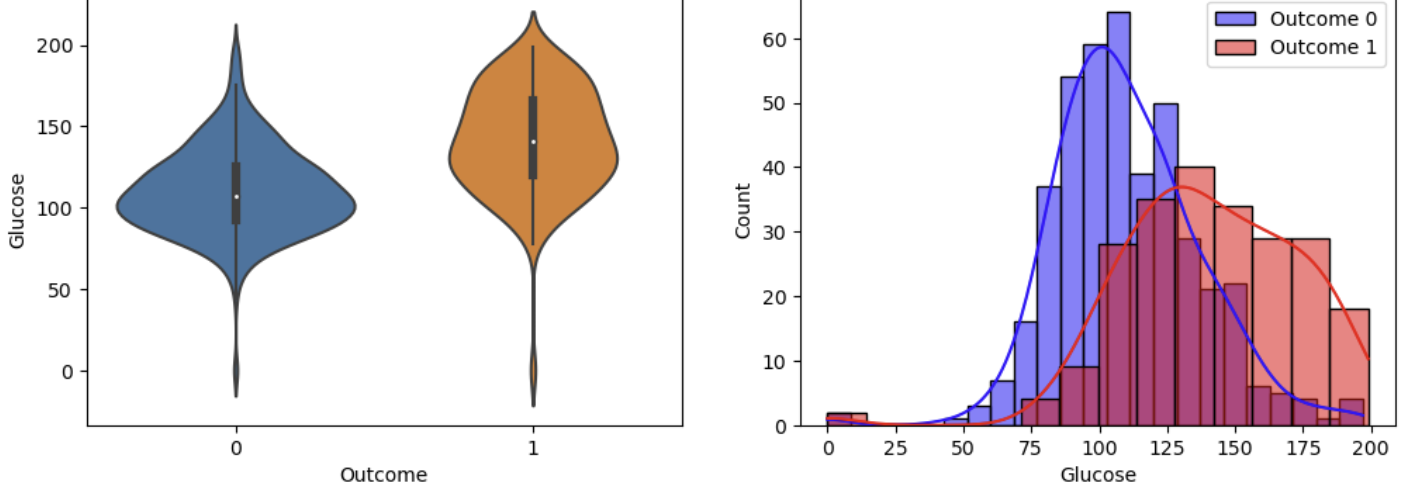
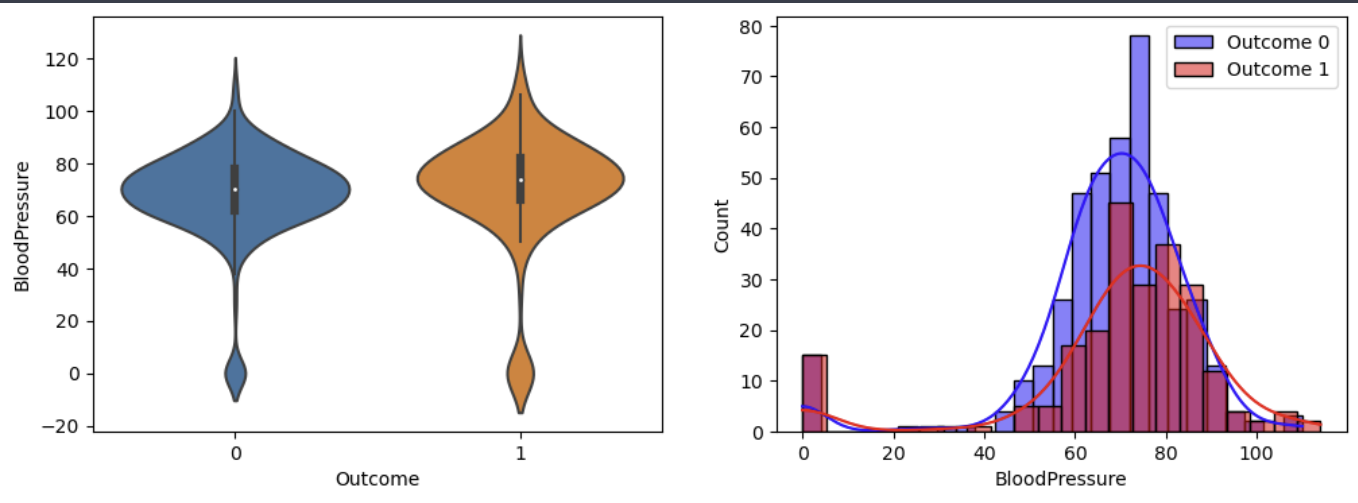
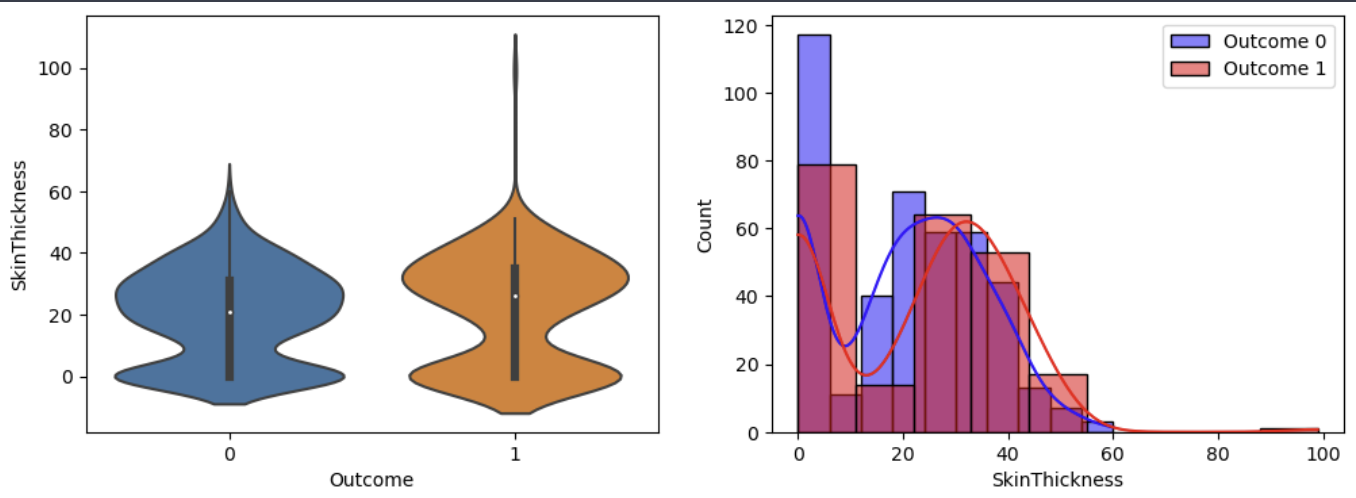
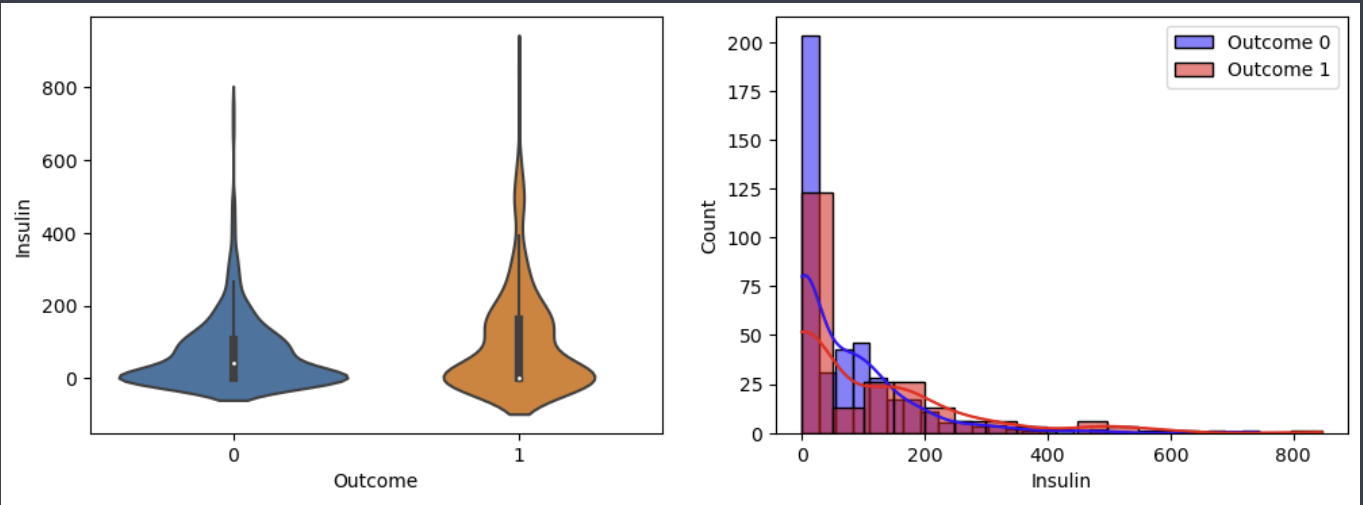
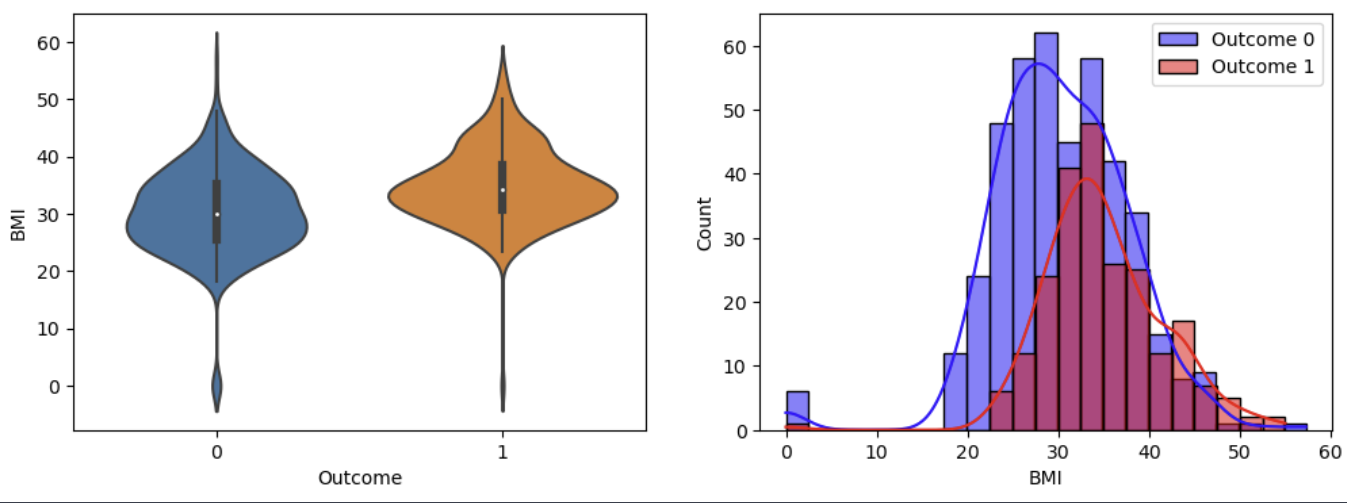
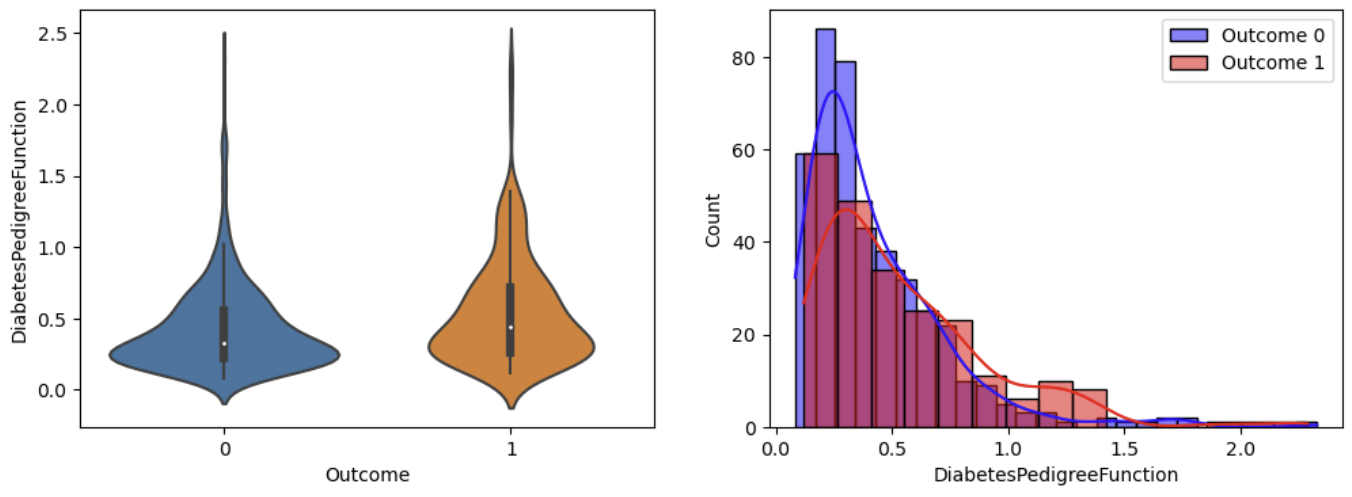
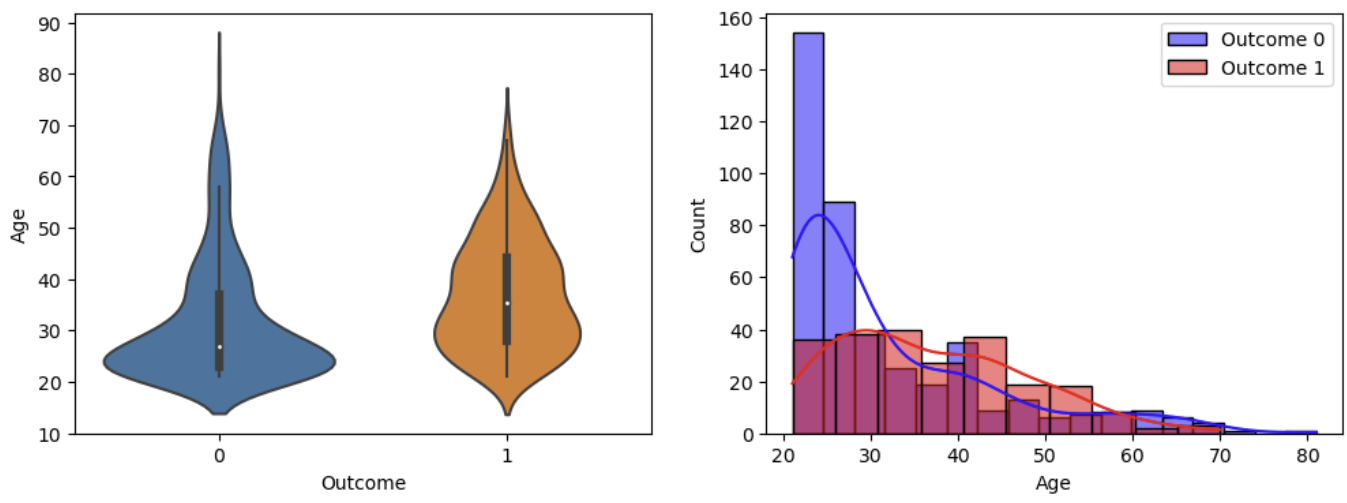
이렇게 자세히 할 필요는 없지만, 결과를 해석해보면
보통 각 변수들은 값이 높을 때가 낮을때보다 당뇨병에 걸릴 확률이 높다는 것이다.
분포를 보면 1일때 분포가 더 높은 값에 빈도가 높다는 것을알 수 있기 때문이다.
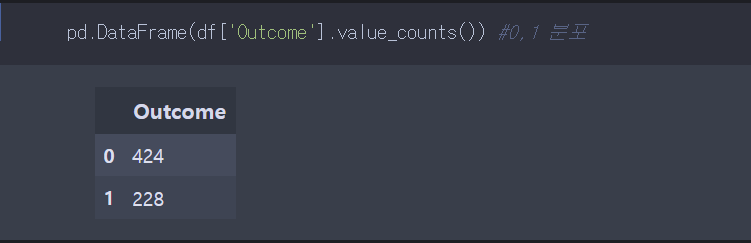
outcome의 값의 분포도 확인한다. 분류를 하는 0, 1 클래스의 비율이 크게 다르면, 모델의 오류가 발생하기 쉽다. 이럴땐 교차검증을 고려하거나, 해결을 해야하기 때문이다. 비율을 보니 나쁘지 않다.

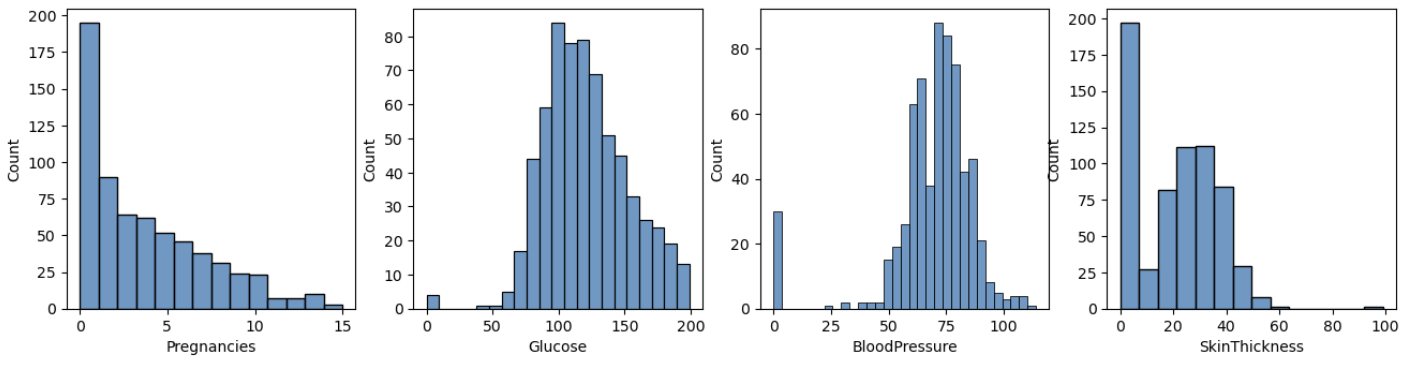
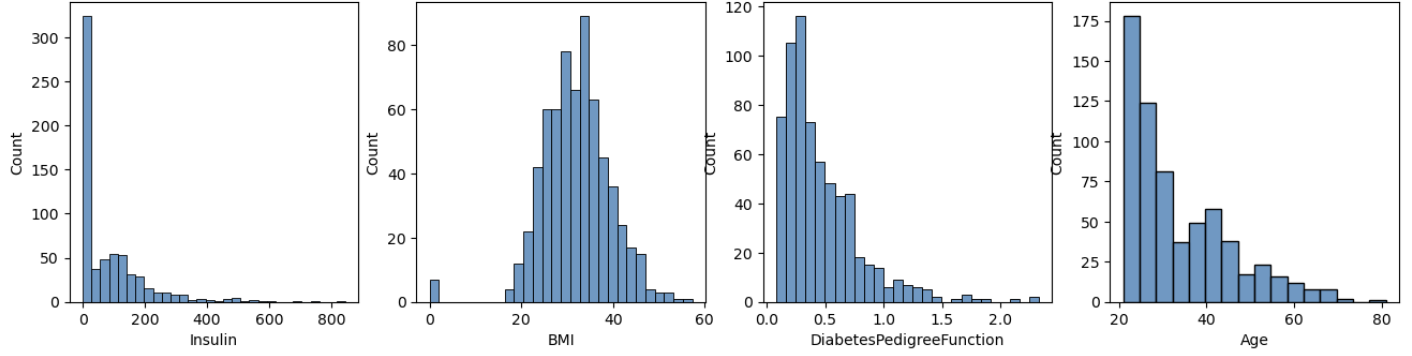
코드는 앞에 바이올린 플랏 코드와 유사하다. 각 칼람별 빈도수를 확인하는 이유는
1. 데이터 스케일링 작업
2. 데이터 오류파악
때문이다. 히스토그램으로 데이터를 살펴보니 오류가 많다.
먼저 단위를 맞춰주기 위해 스케일링도 어느정도 필요할거 같다. 그리고 가장 큰 문제는 0인 값이 너무 많다.
인슐린, bmi, 피부두깨등이 0인 경우는 실제 생활에서 있을 수 없다.
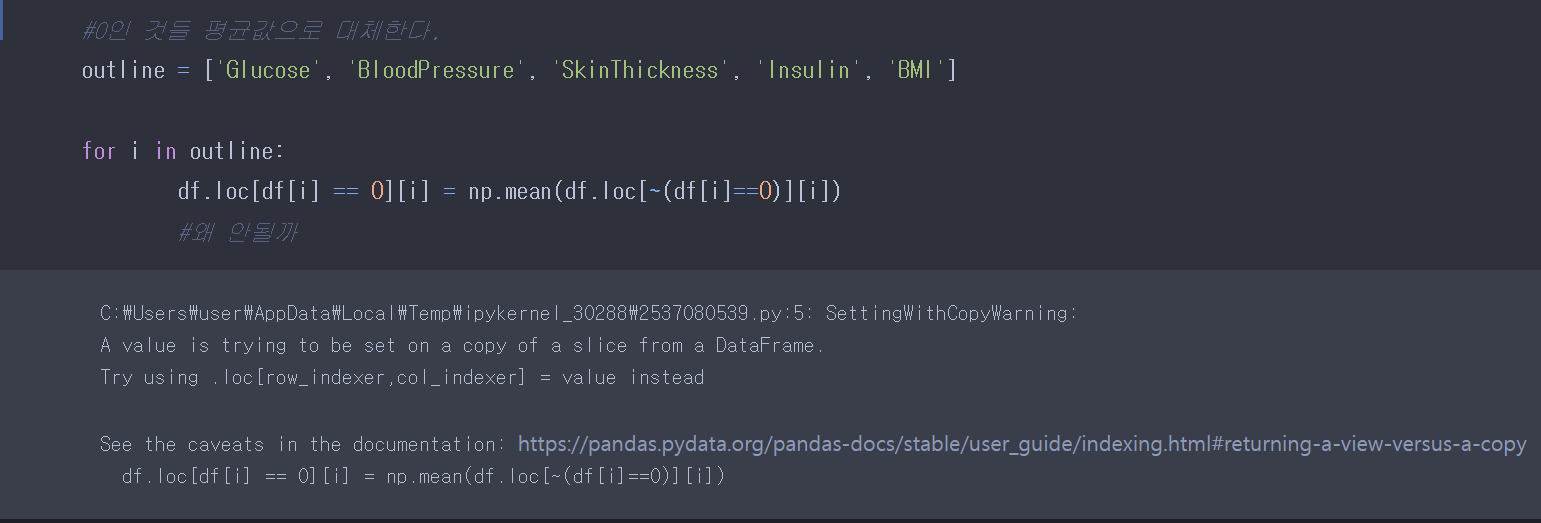
0인부분을 불린인덱싱하여, 0이 아닌부분의 평균을 내서 값을 적용하려고 했는데.. 오류가 발생했다.
그냥 쉽게 replace를 이용하면 됐는데, 너무 어렵게 생각했다..(여기서 해결하는데 한 30분 걸린거 같다..)
다시 replace를 사용해서 쉽게 풀어보면

해결완료!

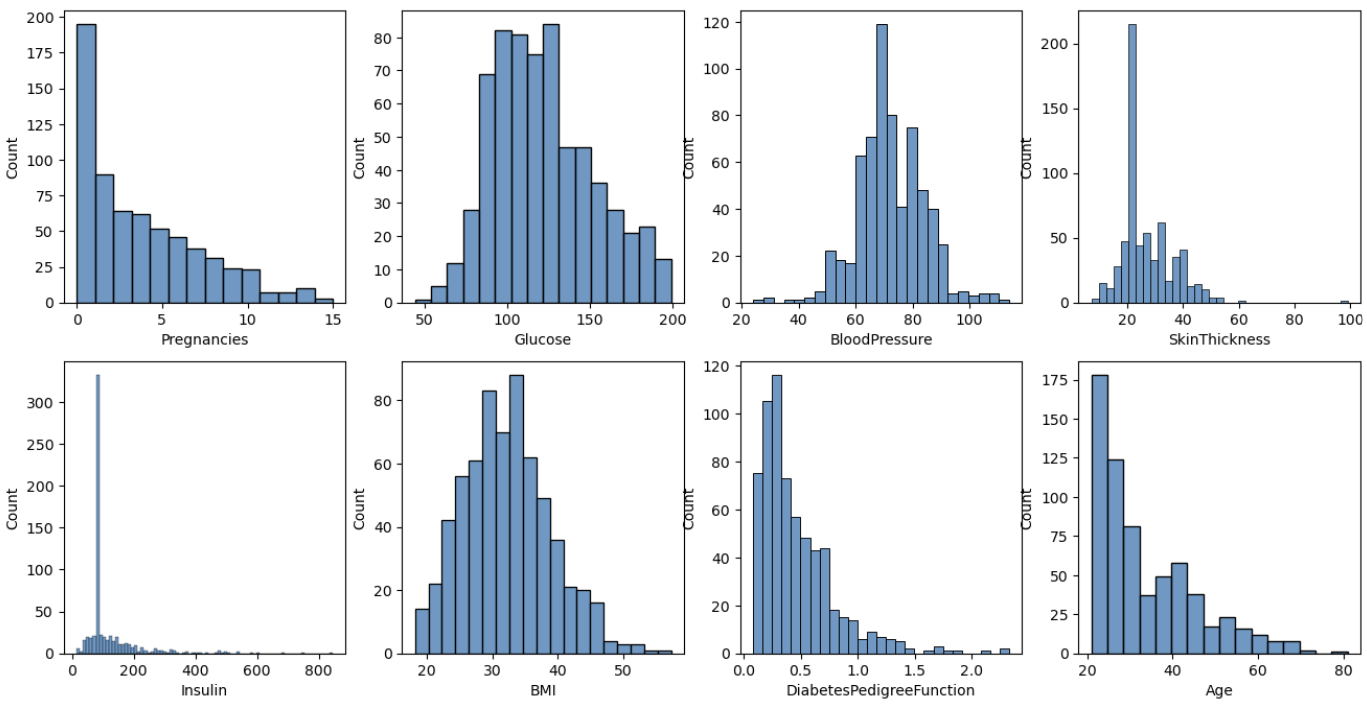
다시 그래프를 재확인하면, 0이었던 값들이 없어진것을 확인할 수 있다. pregnancies는 임신횟수이니 계산에서 제외했다.
- 마무리하며
일단 이번에 탐색적 분석을 통해, 어느정도 데이터를 파악했다. 다음 시간에는 데이터 스케일링과 모델링 적용, 평가를 해보겠다.
'Python > 코딩 실습' 카테고리의 다른 글
| 데이콘 기본 ML 대회에서 알게 된 것들 (왕초보편) (2) | 2023.10.06 |
|---|---|
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
| [1일 1 캐글] Default of Credit Card Clients Dataset, PCA 이용 (0) | 2023.05.31 |
| 1일 1 캐글 프로젝트 시작(feat. 머신러닝) (0) | 2023.05.29 |
| [Pandas 데이터 전처리 100문제 실습] (Grouping part) #44~55 (1) | 2023.04.01 |