
1일 1 캐글 프로젝트 첫 날이다. 첫날은 간단한 것부터 시작하려고 한다.
위의 데이터에서 상관 분석을 통해 상관 관계를 시각화 하고, 그것을 바탕으로 상관도가 높은 부분은 PCA분석으로 차원을 축소하려고 한다.
목차
- 데이터 간단 탐색
- 상관 분석(with sns 히트맵)
- 차원축소, PCA(ADsP 내용 복습)
- 모델 성능 평가
먼저 데이터 셋을 로드한다.
많지 않아 보이겠지만 칼람만 25개이다.
먼저 ID는 불필요해 보이니, 제거를 한다. 이후 drop함수를 이용하여 타겟과 피처들을 나눈다.
(tip ! : X_features예시와 같이 데이터 프레임에서 타겟값만 drop하고, inplace = False로 지정하면 쉽게 분리할 수 있다.)
그리고 피처의 이름이 너무 복잡하여 헷갈린다. 이름을 알아보기 쉽게 함께 변경을 해줬다.
피처의 개수가 많아 ADsP에서 배운것처럼 연관성이 많아져 다중 공산성이 발생 할 수 있다.
따라서, 먼저 상관 분석을 시행한다.
뭔가가 이상한데.. 하면서 문제가 발생했다.
plt.plot(figsize=(14,10)) 이 코드가 문제였다.. plt.figure(figsize=(12,12))로 변환하여 크기를 표현해야했는데, 마음이 급했다. 수정하고 다시 시각화를 구현하면,
코드를 잠깐 설명하면,
corr = X_features.corr() 이것을 통해 상관도 값을 뽑아낸다. 뽑아낸 것을 객체에 할당했다.
annot = True : 히트맵 안에 숫자를 기입
fmt = '.1g' : 소수점 첫째자리 반올림
이제 PCA변환을 한다.
잠깐 배운 내용을 복습하자면, PCA와 함께 StandardScaler를 사용하는 이유가
(cf.ADsP: PCA는 공분산 행렬과 고유값을 사용하기 때문에 표준화를 시켜야한다. 공분산 행렬은 표준화가 되어있지 않기 때문에 단위에 매우 민감하기 때문이다. 민감하지 않은 것을 사용하려면 상관계수 행렬을 사용해야 한다
상관계수는 공분산을 각 편차의 곱셈으로 나눠주어서 표준화를 시킨다.)
다시 원래 내용으로
리스트 축약 방법을 사용하여 변수명을 선택해줬다.
PCA는 2개만 사용했다. 밑에 결과를 보면 알다시피 PCA 2개를 사용했을때 설명할 수 있는 데이터의 분산 정도가 95퍼가 넘는다. 그래서 2개만 일단 사용했다.
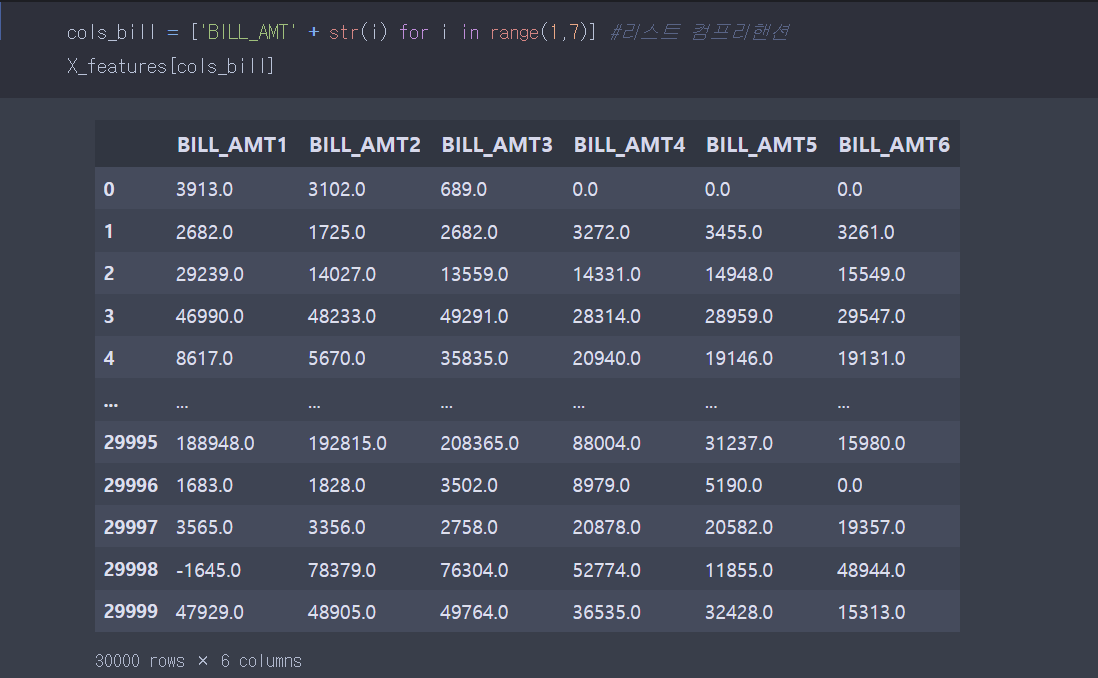
25개 데이터 중 일부만 선택하고 싶었기 때문에,
cols_bill = ['BILL_AMT' + str(i) for i in range(1,7)] 코드를 이용하여 일부만 뽑아줬다.
**사용예시(일부 추출시)
이제 만든 모형을 평가해본다.
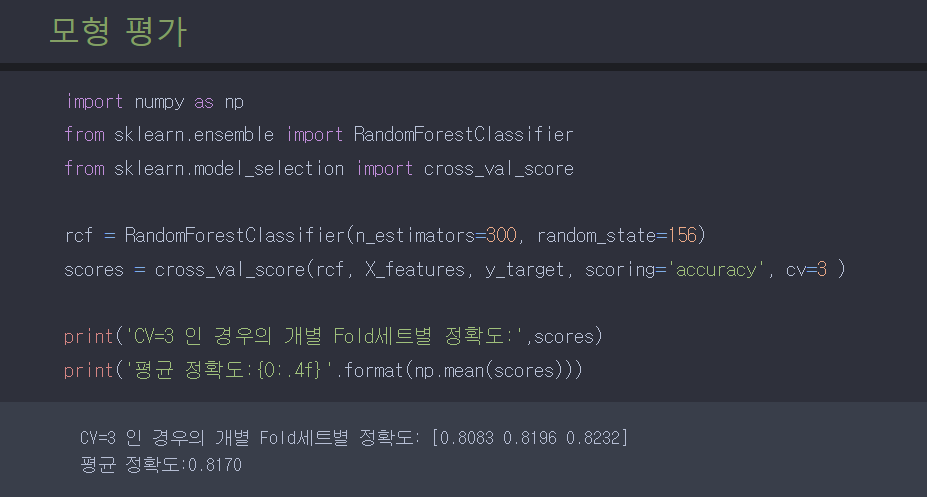
모든 데이터를 사용했을때 보다 정확도가 높지는 않겠지만, 이정도면 준수하다고 할 수 있을 거 같다.
마무리하며: ADsP에서 자격증 전체적인 내용을 공부하니, 실습이나 코드를 짤때 더욱 직관적으로 이해하고 알기 쉬워졌다. 평상시에 넘어갈 수 있는 작은 행동에 대한 원인들을 이해하고 넘어가니, 공부에 재미가 있다.
오늘은 짧은 내용으로 글을 썼지만, 다음은 재밌는 주제로 분석을 제대로 해보겠다.
'Python > 코딩 실습' 카테고리의 다른 글
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
|---|---|
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |
| 1일 1 캐글 프로젝트 시작(feat. 머신러닝) (0) | 2023.05.29 |
| [Pandas 데이터 전처리 100문제 실습] (Grouping part) #44~55 (1) | 2023.04.01 |
| [Pandas 데이터 전처리 100문제 실습] (Pivot part) #83~86 (1) | 2023.03.31 |