이번 카테고리는 데이터 분석 중 80%시간 과정을 차지하는 판다스 데이터 전처리 연습을 할 것이다.
시작 전, 구글링을 통해 전처리 100문제를 올려놓은 좋은 사이트를 들어간다. (제 자료는 아니고, DataManin분께서 직접 만드신 자료입니다.)
이번 전처리 100문제 실습 파트에서는 위의 링크에서 문제들을 직접 풀어보고, 설명하는 내용이 될 거 같다.
코딩을 잘하지 않아서, 비효율적이고, 오류가 발생할 수 있으니, 직접 링크를 들어가서 공부하는 것을 추천한다.
먼저, 최근에 배운 Pivot에 대한 문제를 먼저 풀겠다.
Pivot 문제 풀이
[사용 데이터 : 국가별 5세이하 사망비율 통계 : https://www.kaggle.com/utkarshxy/who-worldhealth-statistics-2020-complete Dataurl = ‘https://raw.githubusercontent.com/Datamanim/pandas/main/under5MortalityRate.csv’]
#83

문제풀이:

먼저 데이터프레임을 불러온다. Indicator 칼람을 삭제하라고 하였으니, drop 메서드를 사용한다.

위의까지 완료했으면 신뢰 구간을 제거한다.
여기서 나의 풀이는 답지에 나와있는 풀이와 다른데, lambda함수와 apply함수를 이용하여 풀어보려고 했다.
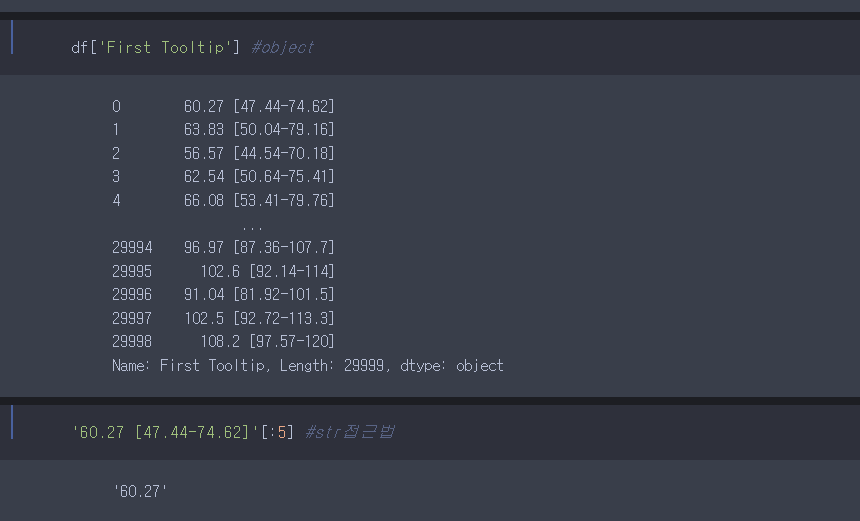
df['First Tooltip']를 찍어봐서 dtype이 object인 것을 확인했다. 이후에는 스트링 접근법으로 문제를 풀 생각을 해봤다.
>lambda함수를 이용하여 전체 시리즈에 적용하기.
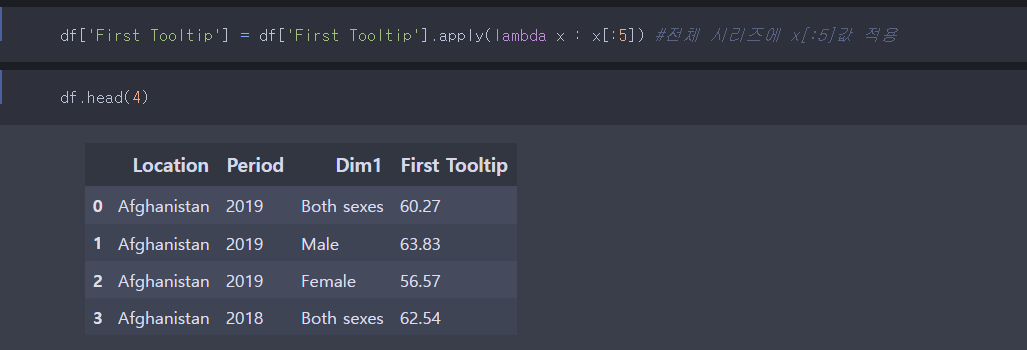
겉으로 봤을때는 답이랑 별 다른점이 없다. 하지만 이렇게 푸는 방식은 틀렸다. 나중에 문제를 풀다보면 오류가 발생하기 쉽다. First Tooltip의 값들이 신뢰구간 전까지의 숫자 자리가 4자리라는 보장이 없다.
좀더 근본적인 문제 해결 방식이 필요하다.
답지에서는 split함수를 이용하였다.
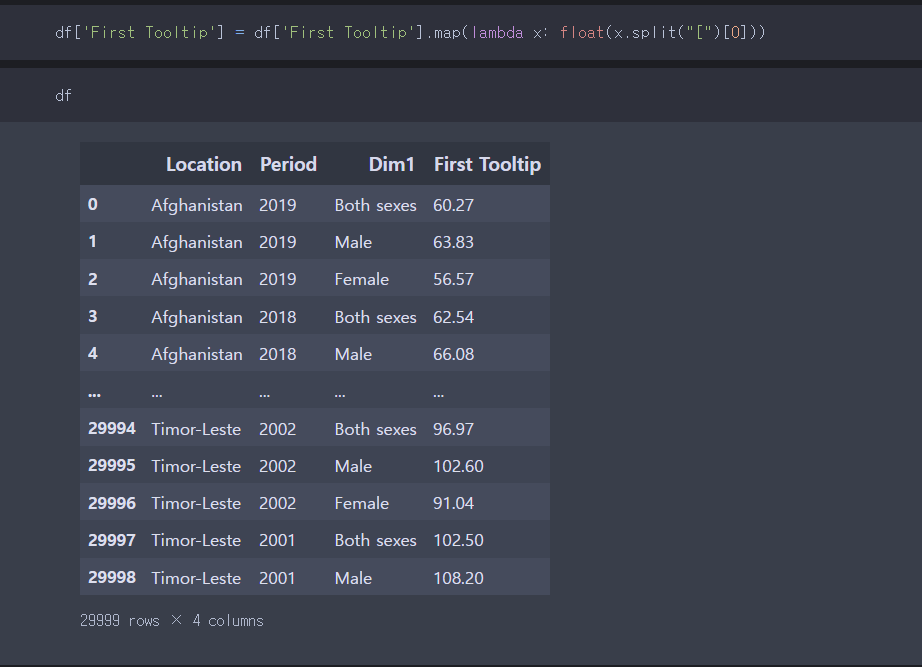
아직 split 함수는 약하다.. 좀 더 연습이 필요하다.
#84
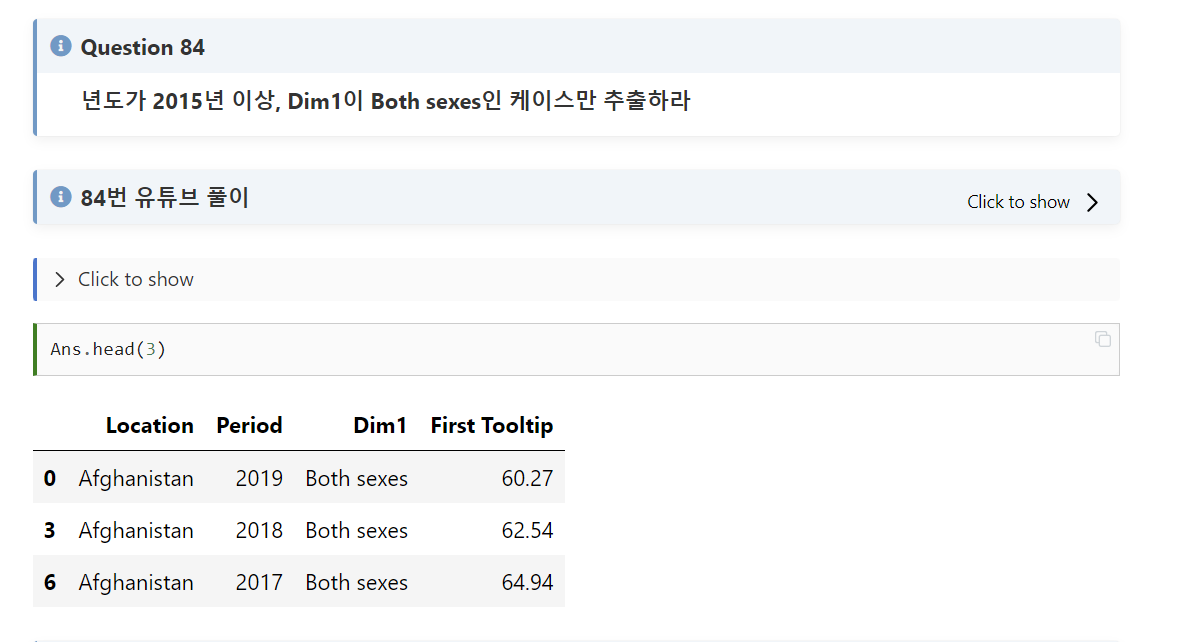
문제풀이:
이 문제는 비교적 쉽다. 다양한 조건에서 불린 인덱싱을 사용하면 해결가능한 문제이다.
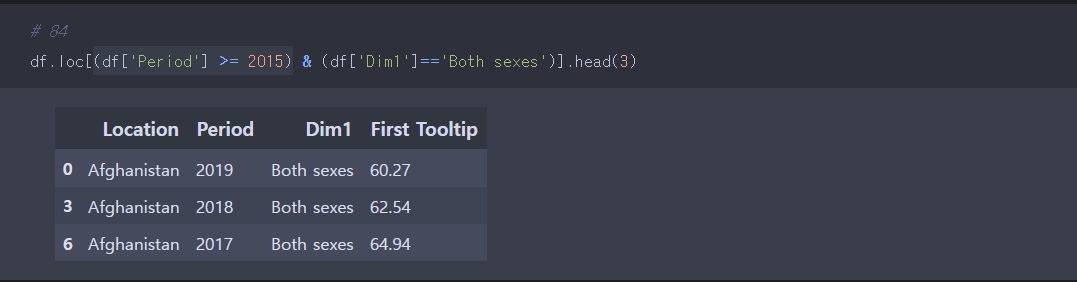
df.loc[불린 시리즈]를 넣어 필요한 데이터프레임만 추출한다.
#85
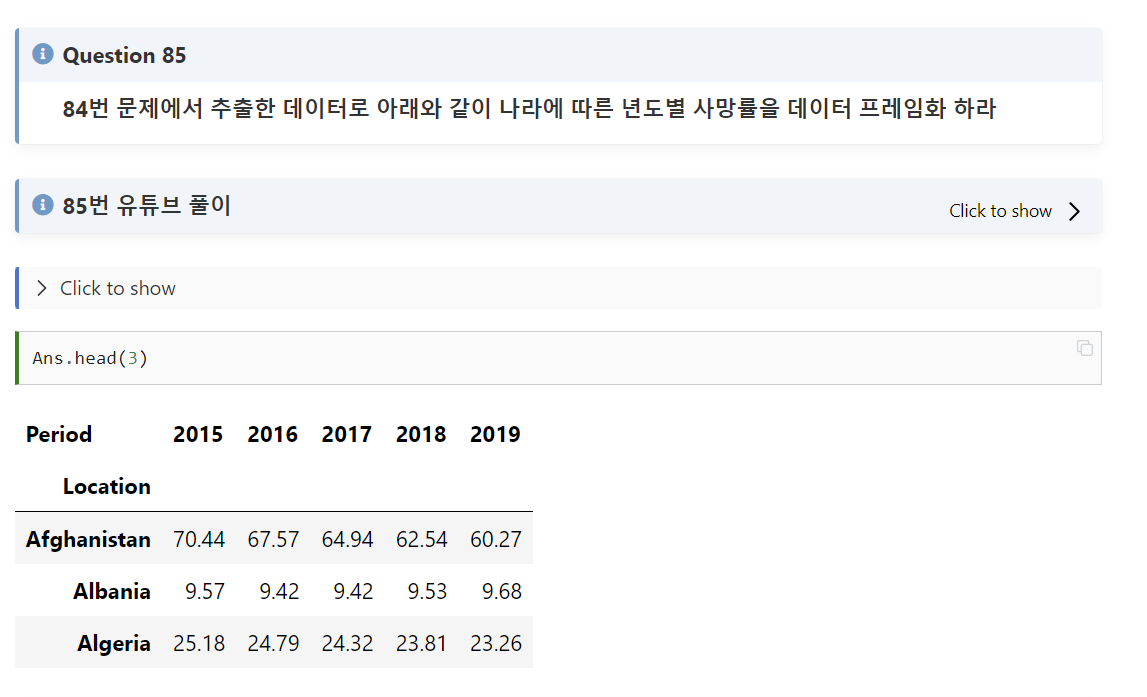
문제풀이:
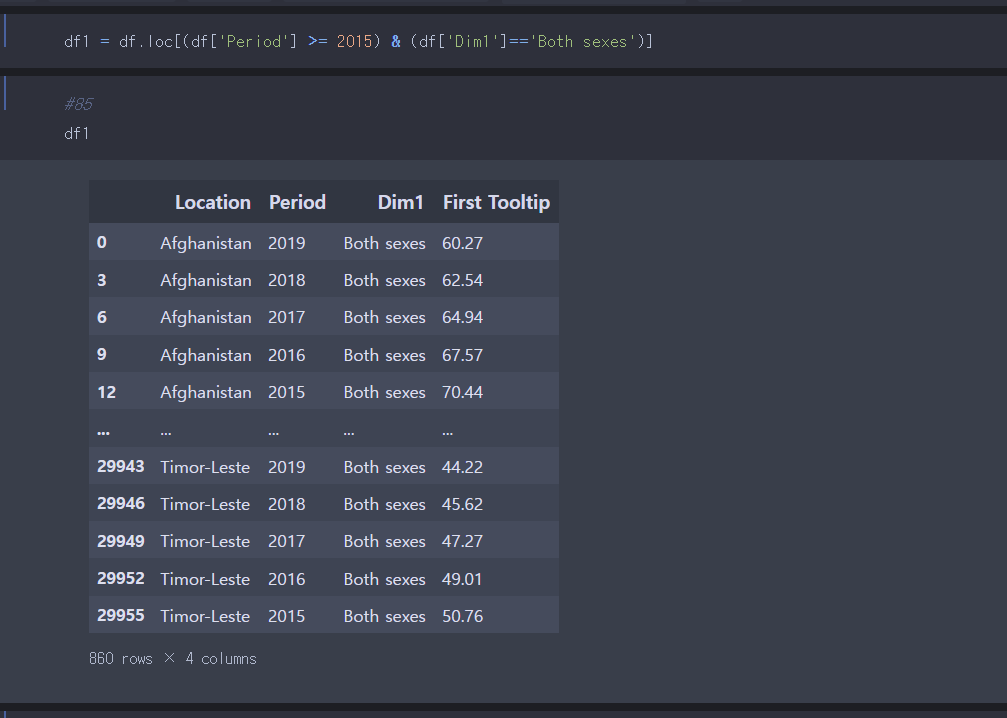
df1이라는 변수에 이전 데이터를 저장한다.
위의 문제 푸는 방식은 경험상 2가지가 있다
1. groupby이용
2. Pivot_table이용
둘 다 유용하니 다른 방식으로 둘 다 풀어보겠다.
groupby이용
groupby를 지정하면 지정한 부분은 index, 선택한 부분은 데이터가 된다.
예시로 하나의 데이터프레임을 df라고 하면,
df.groupby(열이름)[살펴볼 데이터].agg(집계함수)구조 이다.
위의 문제는 그룹바이와 unstack()메서드를 이용하여 풀 수 있다.
groupby를 먼저 해보면,
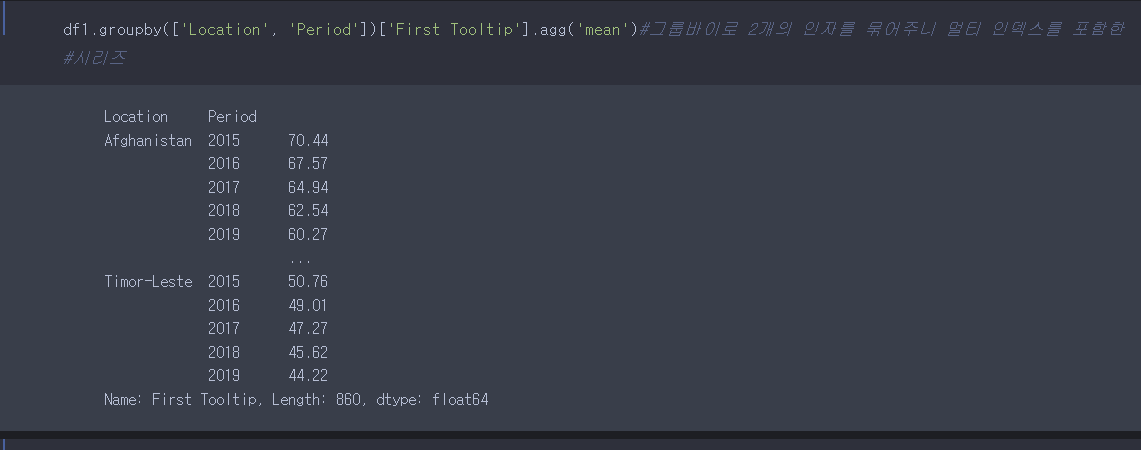
멀티 인덱스를 가진 하나의 시리즈가 탄생한다.
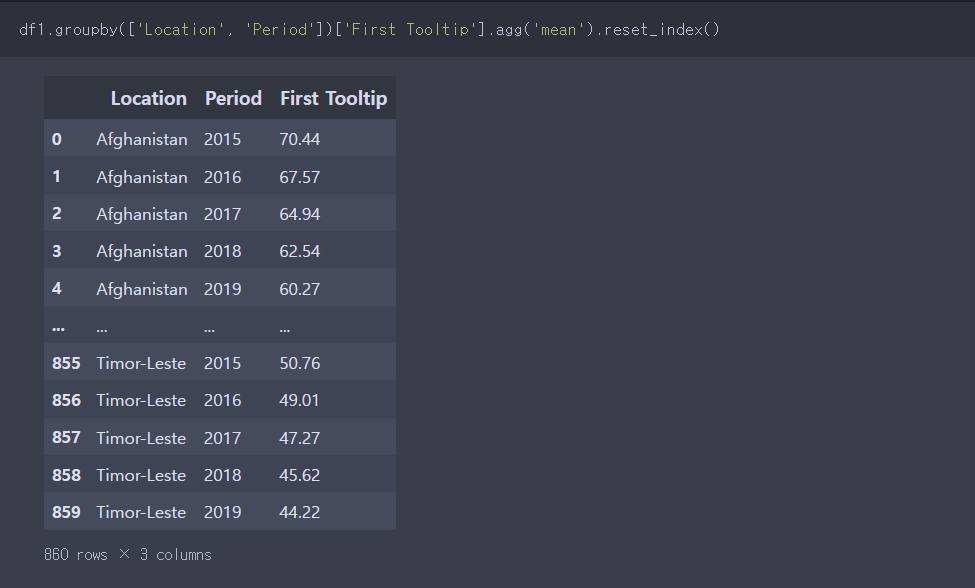
우리는 데이터 프레임으로 보고 싶으니, reset_index()를 이용하여 앞에 인덱스를 초기화함과 동시에, 데이터프레임으로 만들 수 있지만, unstack()을 이용하여 앞에 인덱스 한개(period)를 colums로 옮기면 된다.
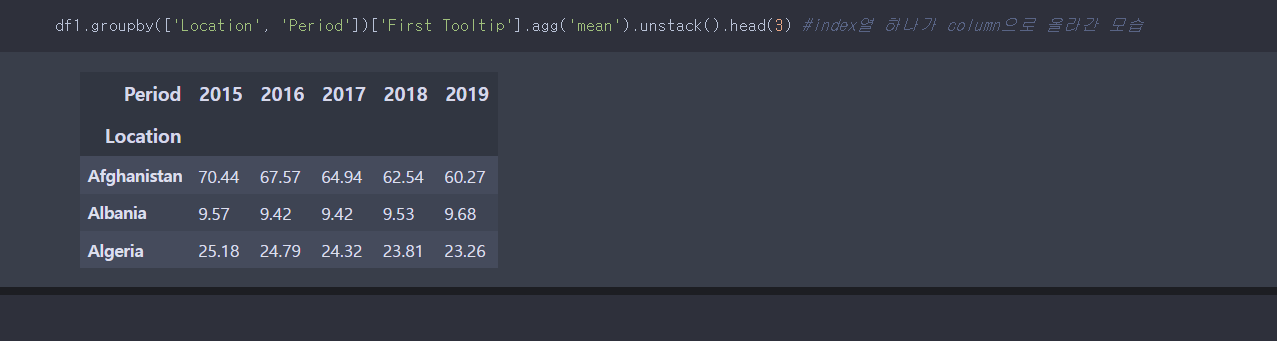
pivot_table이용
뭐 이 방식은 이해보다는 정해진 함수를 쓰는 방식이어서, 답만 작성해보겠다.
pivot_table의 방식은,
df.pivot_table(value로 들어갈 열, index=[df의 value], columns=[df의 value중 위 쪽 column으로 들어가게 됨])
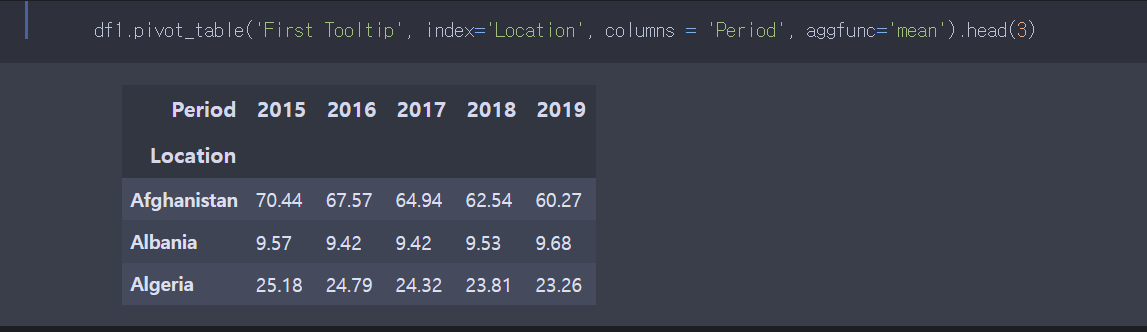
aggfunc = 'mean'으로 넘겨서 중첩되는 값들은 평균 값들로 처리한다.
#86
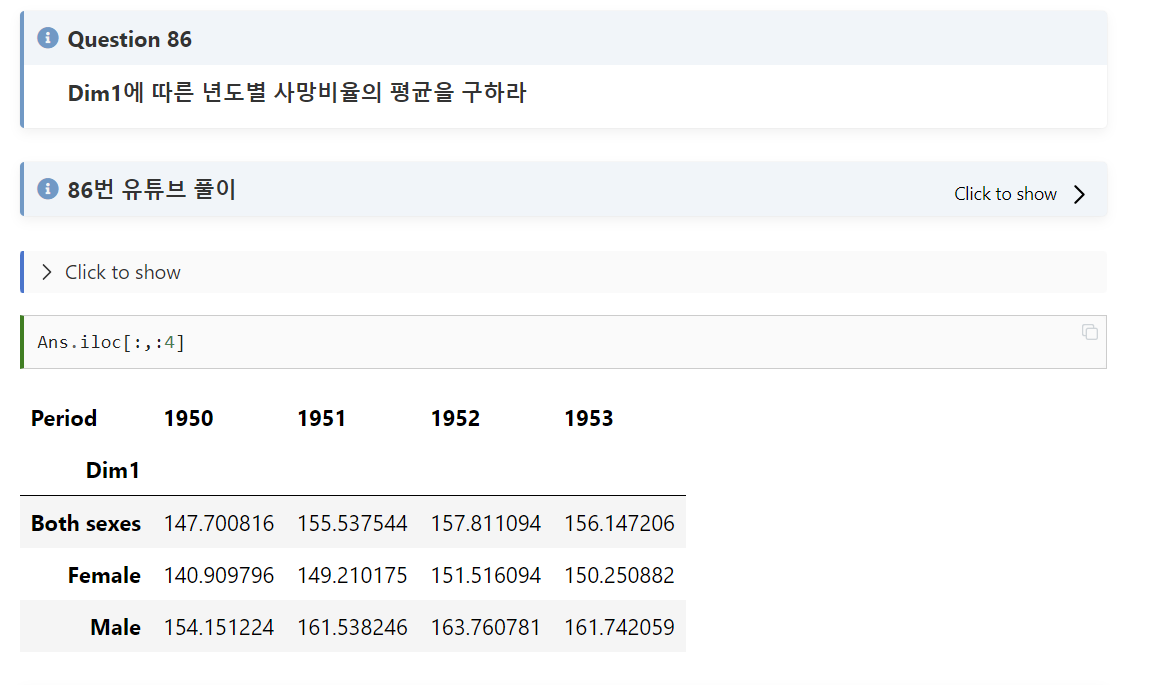
문제풀이:
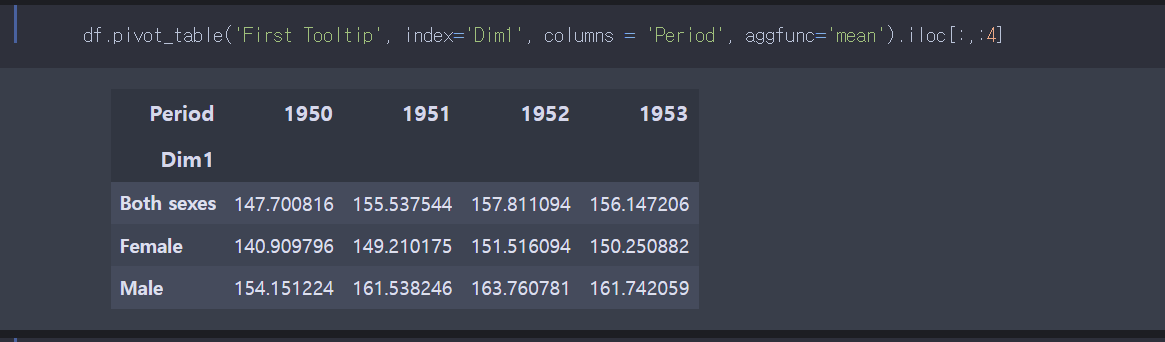
index의 값을 Dim1으로 놓고 iloc 함수를 이용하여 행을 선택하면 된다.
느낀점: 아직은 람다 함수가 조금 미숙한거 같다. 피벗테이블, 그룹바이,어플라이 등등 기본 함수와 함께 쓰일 수 있는 함수들에 대하여 조금 더 집중 해야겠다.
'Python > 코딩 실습' 카테고리의 다른 글
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
|---|---|
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |
| [1일 1 캐글] Default of Credit Card Clients Dataset, PCA 이용 (0) | 2023.05.31 |
| 1일 1 캐글 프로젝트 시작(feat. 머신러닝) (0) | 2023.05.29 |
| [Pandas 데이터 전처리 100문제 실습] (Grouping part) #44~55 (1) | 2023.04.01 |