저번 Pivot에 이어서 오늘은 판다스 전처리 Grouping에 대한 문제를 풀어보려고 한다.
문제를 제공해 주시는 분은 동일하게 Data Manin분의 데이터 학습 자료를 이용하겠다.
(앞서 피벗 테이블에 대해 배웠다. 동일하게 그룹바이도 하나의 데이터 프레임이다. 식이 길어 어렵게 느껴지지만, 피벗과 동일하게 하나씩 인자를 정해주면 쉽게 해결 할 수 있을거 같다.)

Grouping 문제풀이
[사용 데이터: 뉴욕 airBnB : https://www.kaggle.com/ptoscano230382/air-bnb-ny-2019 DataUrl = ‘https://raw.githubusercontent.com/Datamanim/pandas/main/AB_NYC_2019.csv’]
#44

문제풀이:

실행 전에 import pandas as pd로 판다스 부르고, read_csv로 파일을 읽자.
#45

문제풀이:
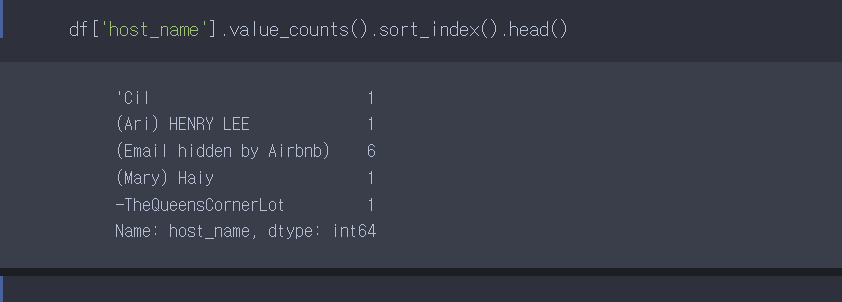
value_counts()와 sort_index()를 활용하여 풀 수도 있고, 그룹바이를 활용하여 풀 수도 있다.

df를 host_name으로 묶고, 묶은 것들의 개수를 나타내는 size()를 적용해서 풀 수도 있다.
#46

문제풀이:
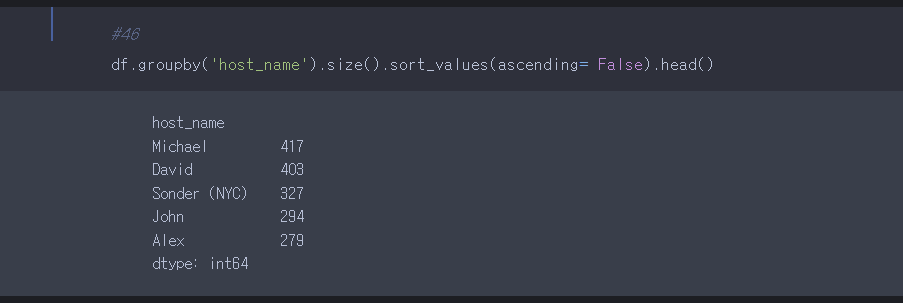
먼저 데이터 프레임을 host_name으로 묶은 size를 추출한다. 이후 sort_values메서드를 이용하여 개수별로 내림차순으로 나열한다. 그 다음은 이 시리즈를 데이터 프레임으로 만들어야 하는데, 방법은 여러 가지이다.
위의 시리즈가 데이터 프레임이 되지 못한 이유는 칼람값이 없기 때문이다 따라서 칼람값을 만들기 위해 reset_index를 이용한다.

다른 방법으로는 직접 데이터 프레임을 만들어주는 방법이 있다. pd.DataFrame을 이용한다.

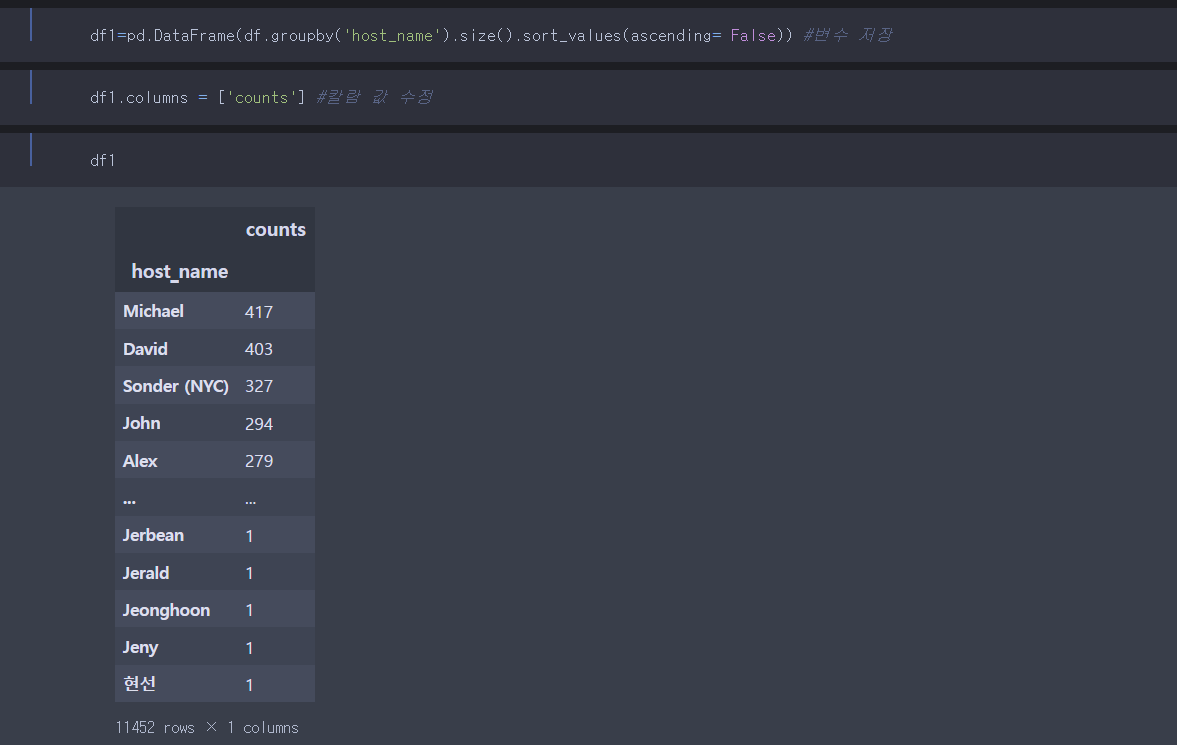
데이터프레임을 만들었으면 빈도수 column을 count로 지정해야한다.
지정해보자.
#47

문제풀이:

먼저 데이터 프레임을 선택한다.
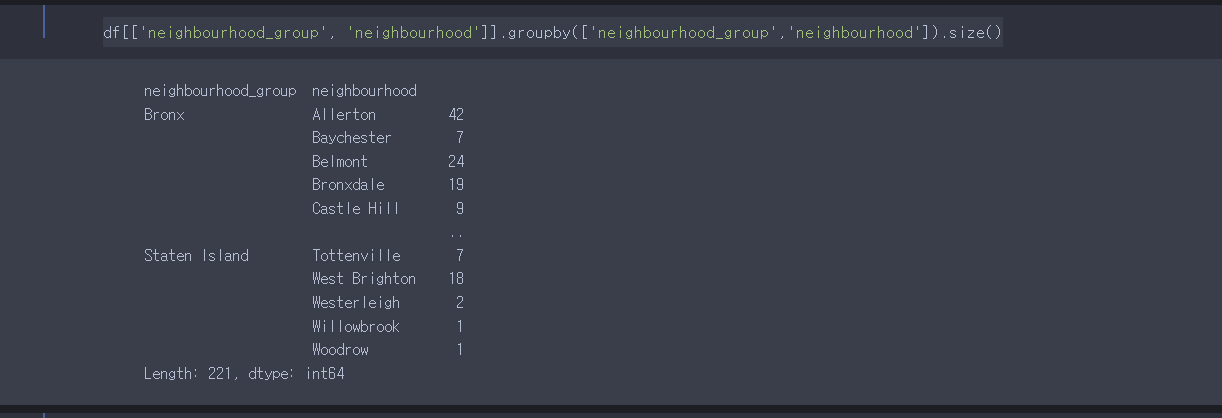
선택한 데이터프레임을 groupby를 사용하여 size를 추출한다.
멀티 인덱스를 가진 하나의 시리즈이니, as_index = False메서드를 이용하여 데이터 프레임으로 변환한다.

#48

문제풀이:
위의 문제를 재사용한다.

쉽게 말하면 그룹 바이를 두번하는 것인데, 먼저 그룹바이를 통해 추출한 데이터 프레임을 df2변수에 저장한다.
그 이후 df2 데이터 프레임에서 neighbourhood_group으로 묶은후 max함수를 적용하면 각 그룹별 최대값이 나오게 된다.
#49
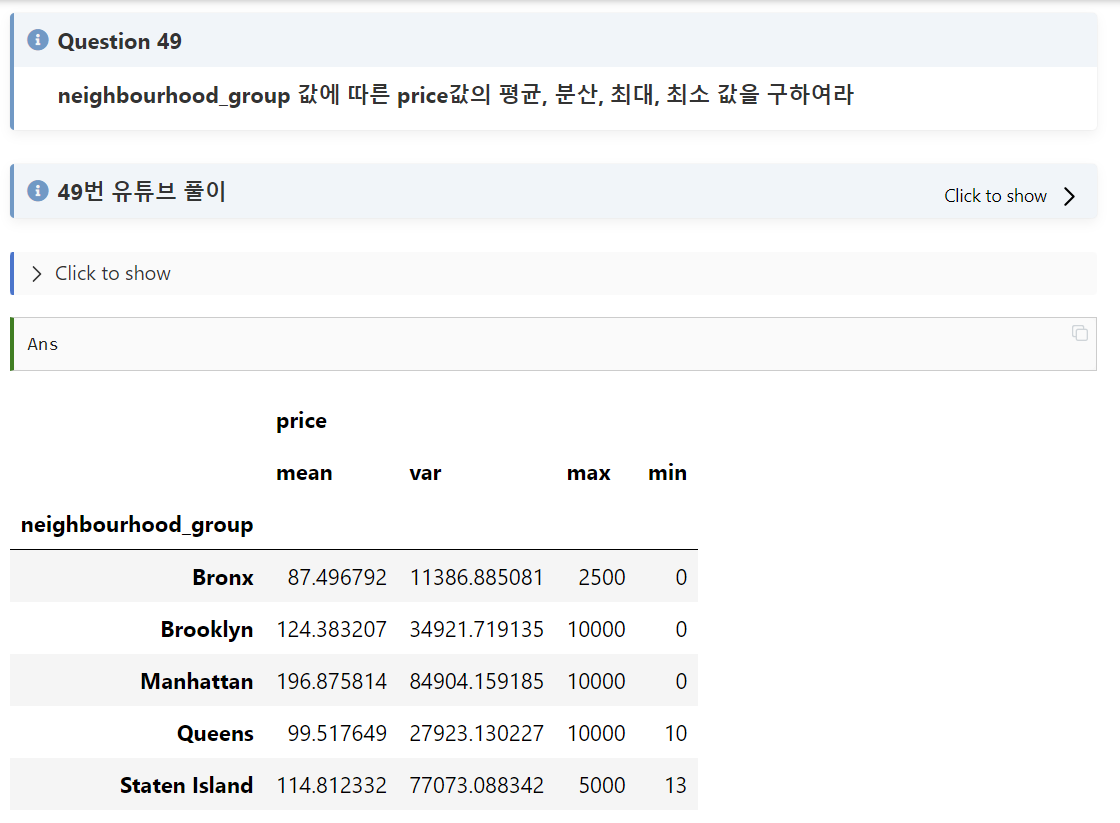
문제풀이:
agg집계함수 방법을 이용한다. agg(함수 열이나 이름)

#50
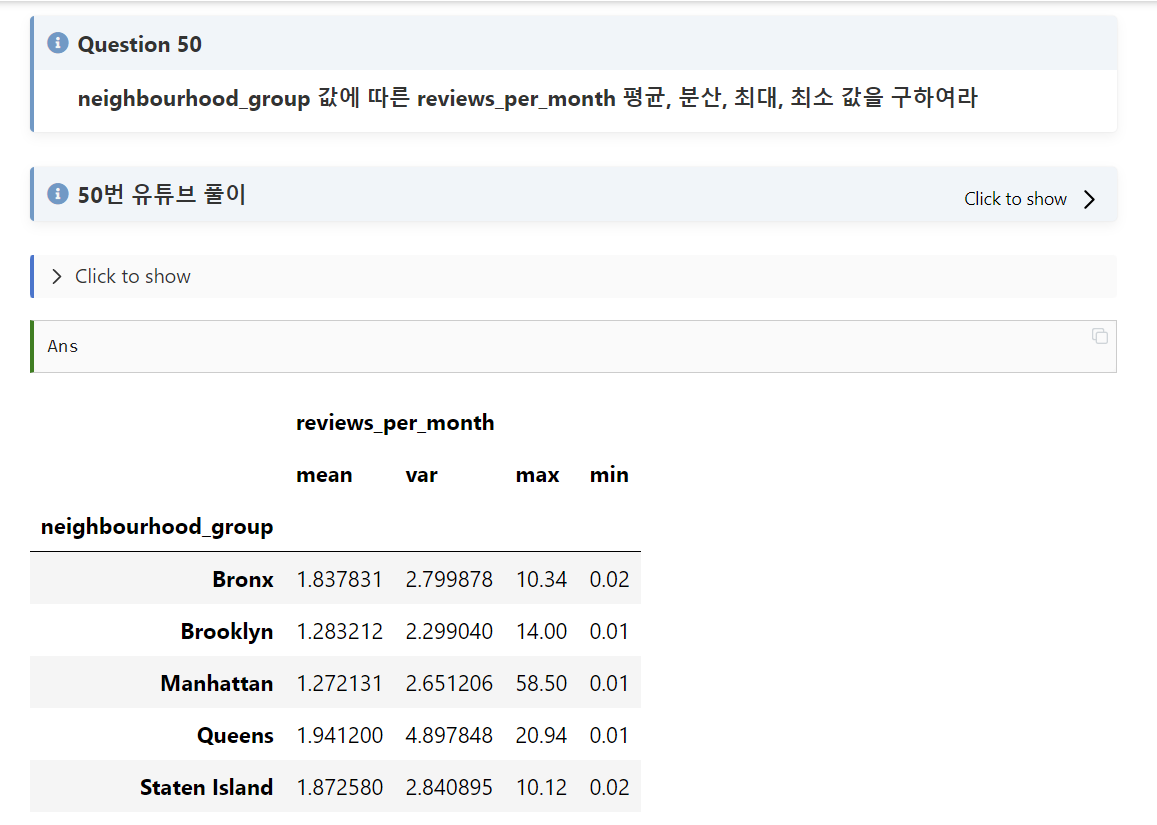
문제풀이:
49번 방식과 문제 풀이 방식이 비슷하다.

#51

문제풀이: 위의 조건을 하나씩 입력한다. groupby의 기본 구조는
df.groupby(그룹으로 묶을 열)[다루고 싶은 데이터].agg(집계함수)
구조이다.
따라서
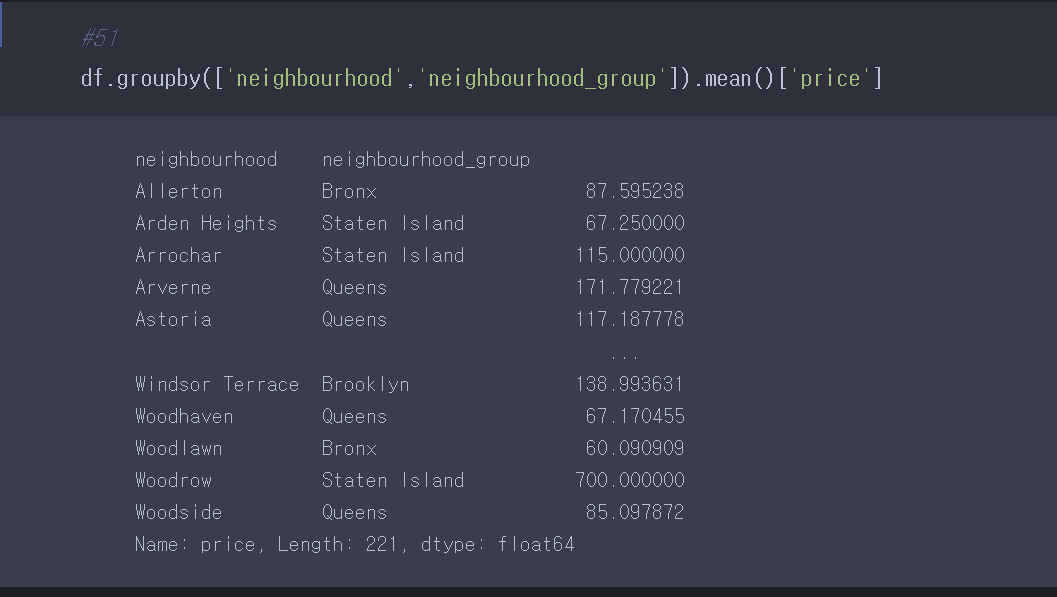
['price']는 앞 부분에 써도 되고, 뒷 부분에 써도 된다. 데이터 프레임에서 열을 선택하는 방식과 동일하다는 것을 알려드리고 위해 저렇게 표현했다.
#52


문제풀이:
피벗테이블 구조이다. 저런 데이터 프레임을 피벗이라고 부르는데, 사실 다른점은 없다. 중첩된 부분을 함수로 처리한다는 것 빼고는 같다.
groupby를 하면 선택한 열들이 인덱스가 된다. 따라서 여러개의 열들이 존재하지만, groupby결과는 시리즈이다.(데이터 프레임으로 만들거나, 두개의 열을 선택하지 않는 이상)
예시를 보여주겠다.

아까 풀어본 51번이 예시이다. 인덱스는 멀티 인덱스로 두개가 지정 되어 있지만, column의 값이 없어 하나의 시리즈이다.
위의 같은 데이터 프레임으로 만들기 위해서는 neighbour_group인덱스와 값들을 칼람으로 만들면 된다. unstack메서드를 이용하여 칼람으로 만들 수 있다.

없는 값들은 NaN으로 처리되고, 중복 값들은 평균으로 처리가 된다.
#53

문제풀이:
53번에서 빈값을 채워주기만 하면 된다. fillna()메서드를 이용하여 빈값을 채워줄 수 있다.

#54

문제풀이: 먼저 데이터를 선택한다.

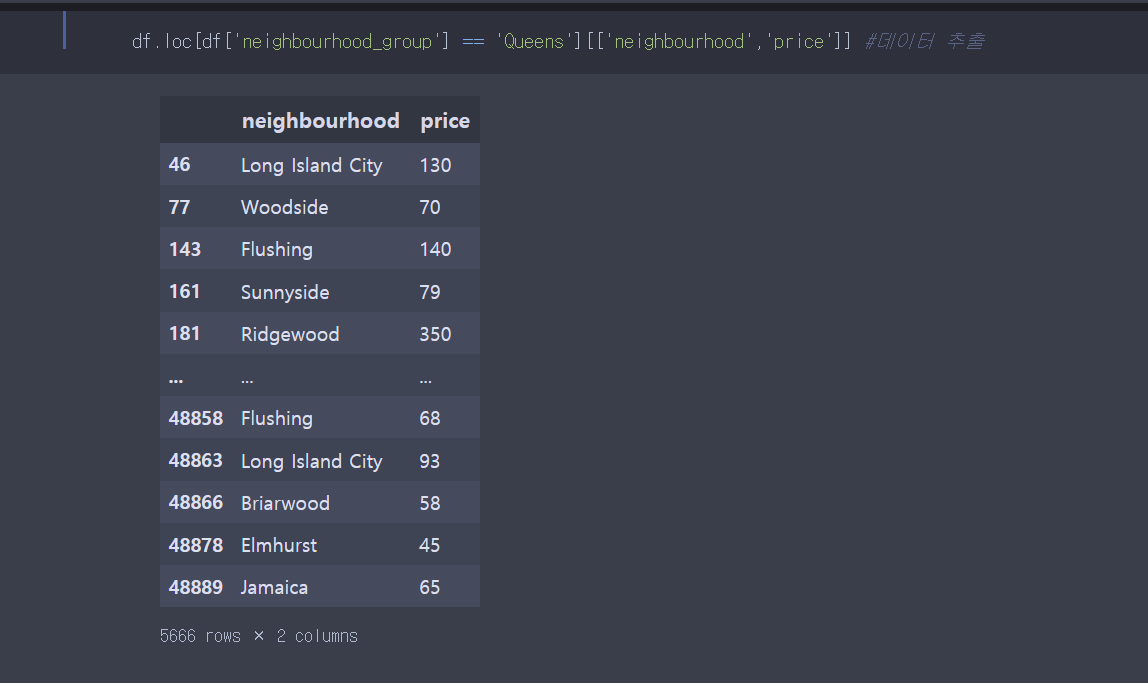
불린 인덱싱을 이용하여 일부 칼람들만 추출하였다.
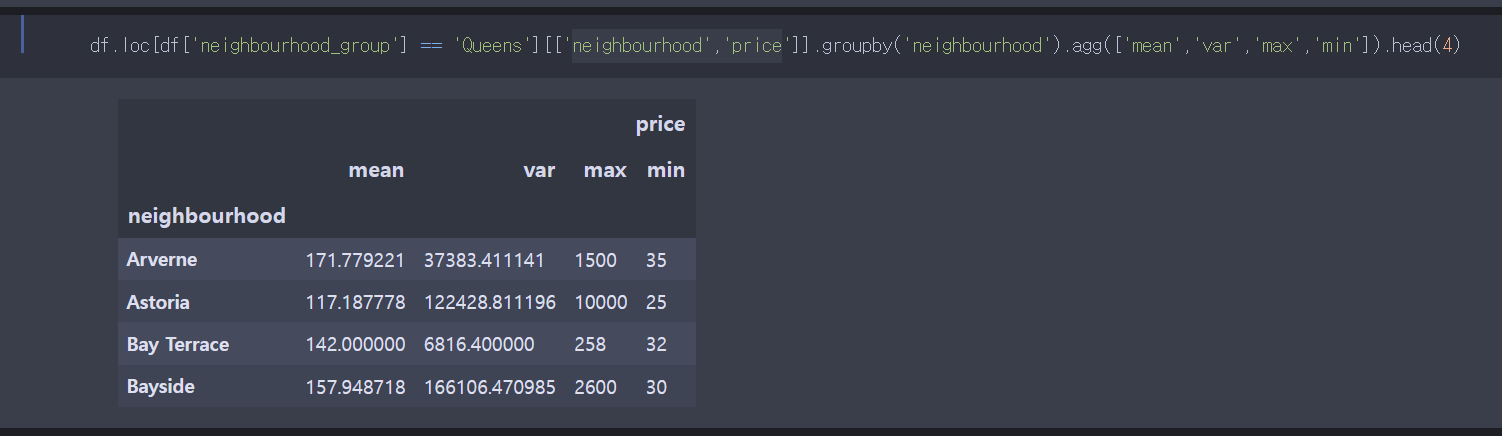
추출한 데이터를 그룹화 시키고, agg함수를 이용하여 집계함수를 입력해주면 된다.
#55

이건 뭐지... 푸는 중... 다 풀고 수정해서 올림...
'Python > 코딩 실습' 카테고리의 다른 글
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
|---|---|
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |
| [1일 1 캐글] Default of Credit Card Clients Dataset, PCA 이용 (0) | 2023.05.31 |
| 1일 1 캐글 프로젝트 시작(feat. 머신러닝) (0) | 2023.05.29 |
| [Pandas 데이터 전처리 100문제 실습] (Pivot part) #83~86 (1) | 2023.03.31 |