
이번 시간에는 Online Retail Data Set 데이터를 갖고 고객 세그먼테이션 정의와 기법을 통해 군집화 실습을 진행할까 한다.
파이썬 머신러닝 완벽 가이드에 있는 내용을 참고하긴 했지만, 전반적인 코드 보지 않고 내가 직접 구현했기 때문에 비효율적일 수 있다.
목차
- data exploration
- data preprocessing
- R, F, M Application
- data scaling
- kmeans
- Evaluation
1. 데이터 탐색과 전처리(exploration, preprocessing)
먼저 데이터 셋을 불러온다
1 StockCode : 제품 코드
2 Description : 제품 설명
3 Quantity : 주문 제품 건수
4 InvoiceDate: 주문 일자
5 UnitPrice : 제품 단가
6 CustomerID : 고객 번호
7 Country: 국가명(국적)
8 InvoiceNo: 주문번호. 'c'로 시작하는 것은 취소 주문df.info()를 찍어보면
데이터 수가 10만건이 넘어가는 것을 확인할 수 있다. 먼저 데이터 안 결측치가 너무 많기 때문에 결측지 제거나 채워주기를 시행한다. 이때 CustomerID가 중요하다. 후에 CustomerID를 기준으로 그룹핑을 실시할것인데 결측치가 있다면 사용할 수 없기 때문이다. 따라서 CustomerID가 nan인 행은 전부 제거한다.
또한 StockCode나 Description같은 것은 RFM기법을 사용하는데 사용이 전혀 되지 않기 때문에 과감하게 삭제했다.
다시 다른 결측치를 제거하기 위해 df.info()를 찍어봤는데
신기하게 모든 결측치가 다 사라졌다.
count의 sort_values를 확인하니 대부분의 국가 데이터가 영국이다.
따라서 영국의 데이터만 선택한다. 그래도 데이터가 36만건이 넘는다. 이제 결측치도 없고 다른 세부적인 작업에 들어간다. 앞에서 전처리와 일부 데이터 셋 선택 작업을 완료했기 때문이다.
살펴볼 것들은
1. R,F,M에 사용되는 제품 단가(Unitprice), 주문 제품 건수(Quantity)가 전부 양수인가?
2. InvoiceNo(주문번호)가 앞글자가 C면 취소, 따라서 취소된 주문들은 행에서 삭제가 필요하다.
라고 생각을 했다.
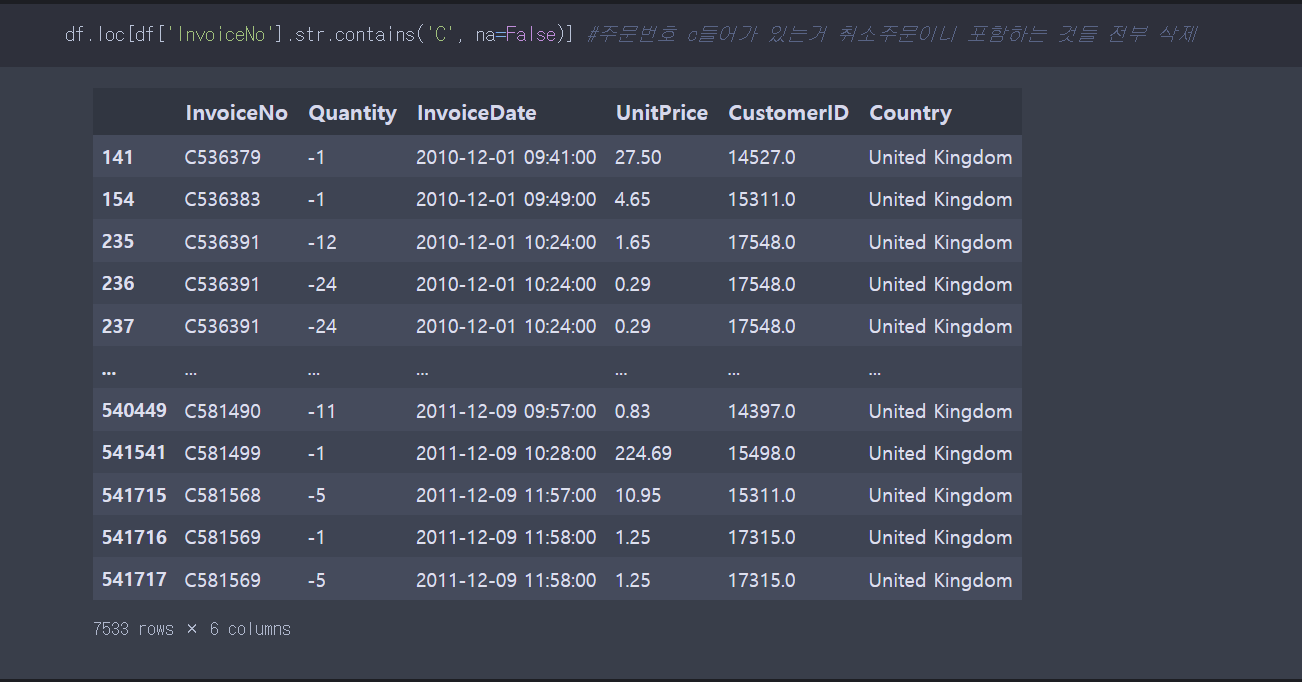
취소 주문을 갖고 있는 함수를 뽑아내기 위해 contains함수를 이용했다. 이 함수가 기억이 안나서 구글링으로 힘겹게 찾았다.. 그리고 na =False로 표시하지 않게 되면, nan값을 반환하기 때문에 na = False로 파라미터를 입력해야한다. 문자열에 접근할때는 .str을 붙여서 접근 해야 한다.
함수 사용 결과 취소 주문들이 7533건이 있는것을 알 수 있다. 이것을 제거하기 보다는 제외한 부분을 불린 인덱싱으로 직접 뽑는게 더 좋은 방법인 거 같았다.
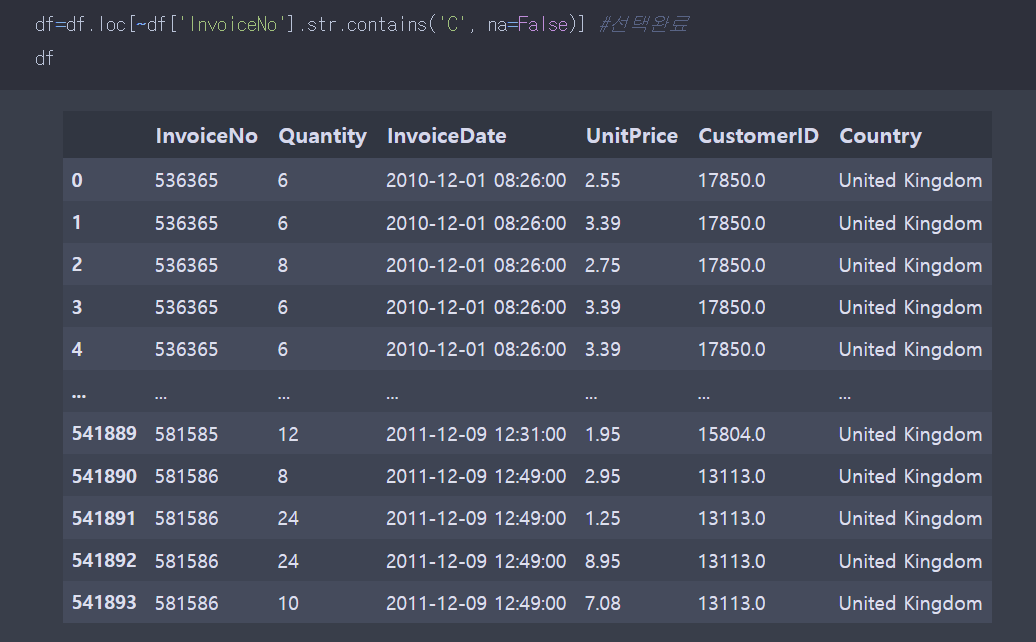
취소 주문을 확인하고 취소가 아닌 데이터를 선택했으면, 제품 단가와 주문 건수가 둘다 양수 인지 확인 해야 한다.

sort_values 함수를 이용하여 오름차순으로 정렬한다. 그렇게 되면 앞에 있는 값이 가장 작은 값이다.
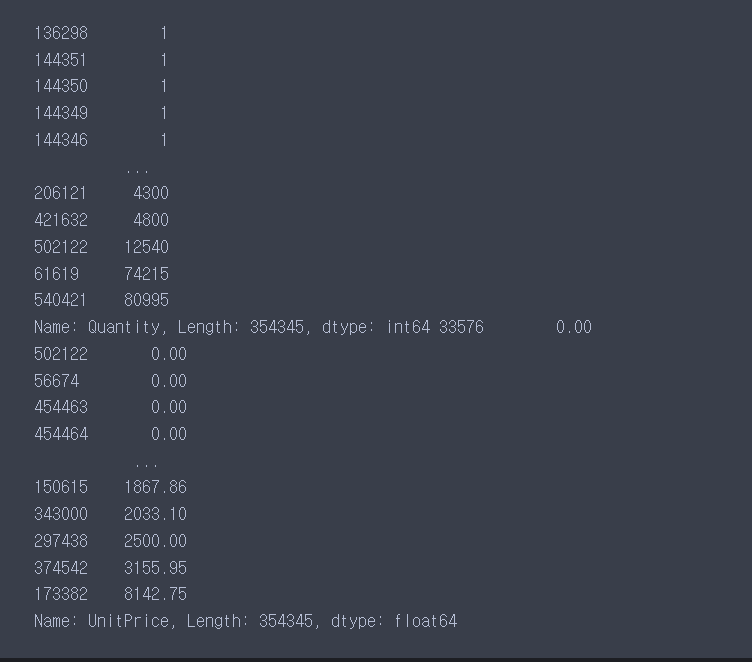
확인 결과 Unitprice의 값중에 0인 값들이 몇개가 있다.
따라서
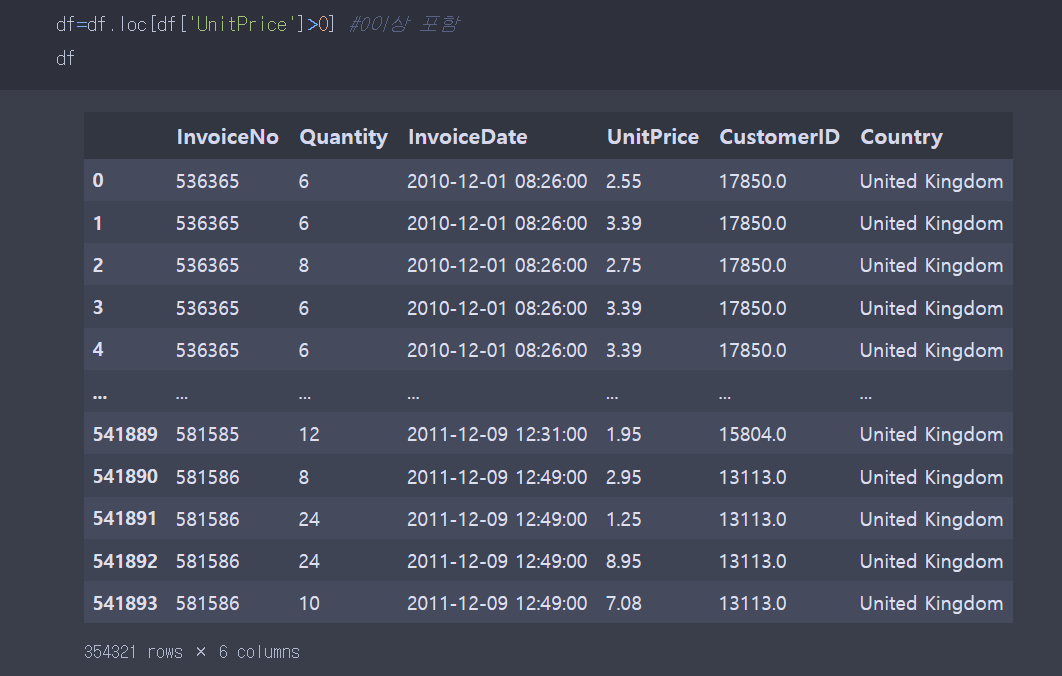
불린 인덱싱으로 0보다 큰 값들만 고른다.

앞에서 쓰이고 역할을 다한 칼람들은 삭제한다.
2. R, F, M 기법 적용(R, F, M Application)
RECENCY(R): 가장 최근 상품 구입 일에서 오늘까지의 기간
FREQUENCY(F): 상품 구매 횟수
MONETARY VALUE(M): 총 구매 금액고객 마케팅 같은 분야에서 특히 이 기법이 많이 쓰인다고 한다. 나의 목적은 위의 R, F, M을 고객 아이디별로 그룹화 하여 각각 구하고, kmeans를 사용하여 군집 분류를 하려고 한다. 그렇기 때문에 R, F, M을 구하려면
| summary RECENCY(R): groupby와 datetime특성 이용 FREQUENCY(F): groupby와 count함수 사용 MONETARY VALUE(M): groupby와 apply함수 사용 |
봐도 이해가 안될 것이다. 코드와 함께 봐보자.
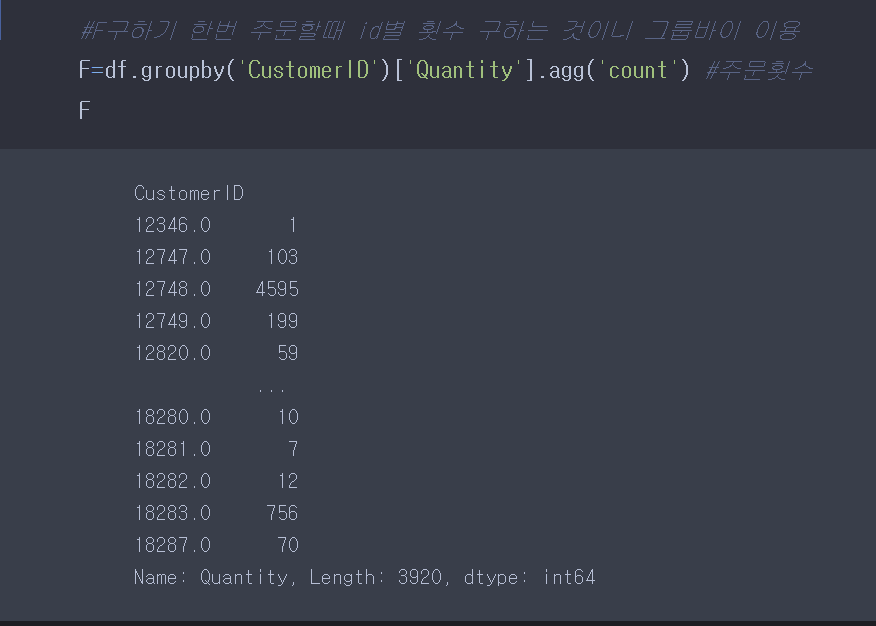
F를 groupby를 이용하여 구해봤다.
저렇게 되면 .......(수정) 귀찮.. 너무 많음 양이 나 자야 돼..
4. 분포 시각화

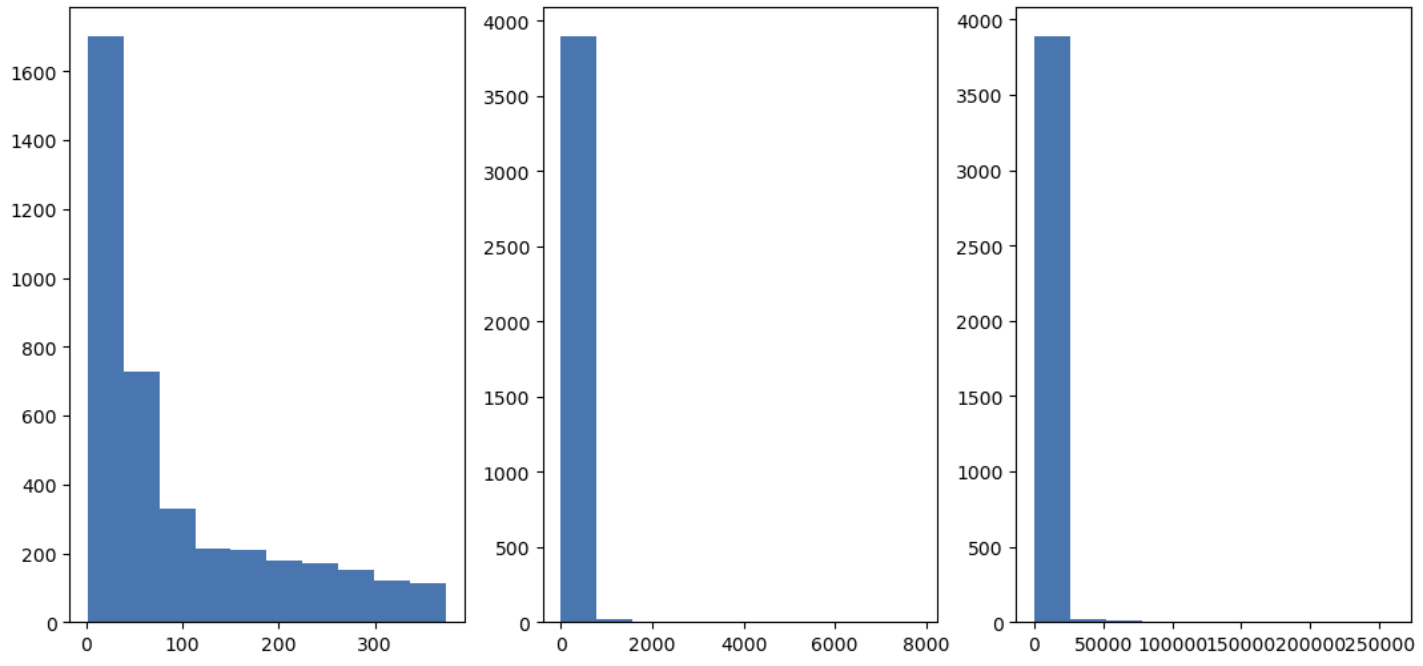
시각화 코드를 이용하여 분포를 확인해봤다. 앞서 EDA탐색적 분석 실습시 코드의 이유를 설명했지만, 다시 한번 더 설명해보면, axes가 그래프를 그려주기 때문이다. plt.subplots을 이용하여 행이 1, 칼람이 3인 작은 플랏들의 tool을 만든다.
for문과 enumerate를 이용하여, 각각 enumeraite돌렸을때 각 칼람별 해당하는 인덱스가 row와 col계산하는 방식으로 수행되어, axs(axes)는 numpy배열인 값을 갖게 되는데, 각각 첫번째 그래프가 axs[0], 두번째 그래프가 axs[1].. 이런 식으로 넘파이의 팬시 인덱식을 이용하여 그래프를 그릴 수 있다.

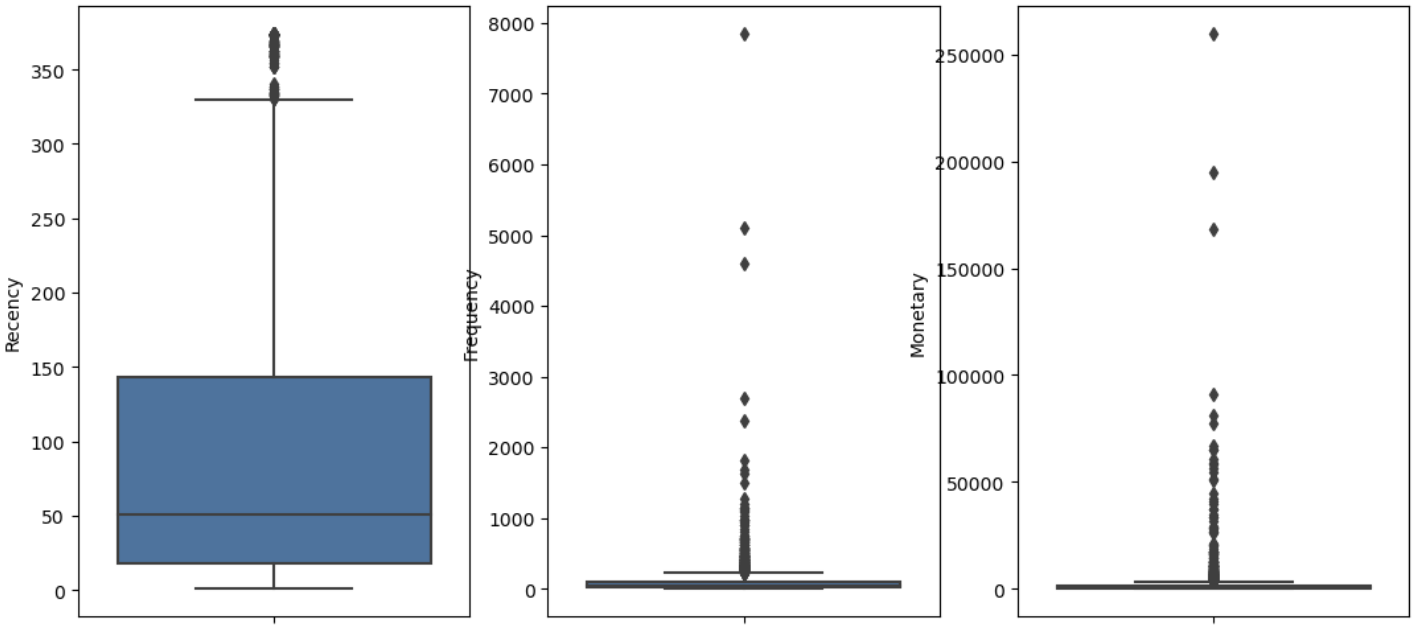
같은 코드를 재사용하여, 박스 플랏으로도 나타내봤다. 자세히 보지 않더라도 피처들의 분포가 엉망인 것을 알 수 있다.
여기서 우리가 할 수 있는 것은 스케일링이다. 그래야 데이터의 단위가 통일 되기 때문이다. 특히 kmeans알고리즘은 거리기반 알고리즘이어서 단위에 특히 민감하다.
스케일링 시행
1. 표준화
2. 로그 변환
정도를 고려해볼 수 있을 거 같다.
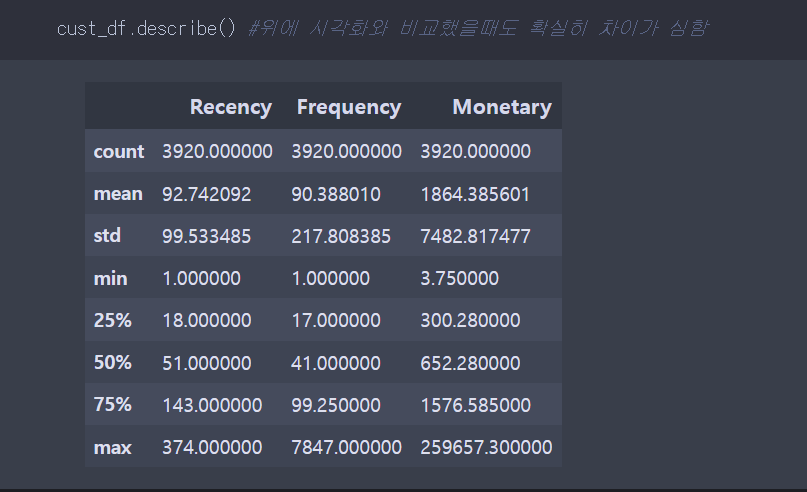
스케일링 전, 수치상의 분포 차이도 확인하기 위해 describe함수도 이용해본다.
5. 데이터 스케일링(data scaling)
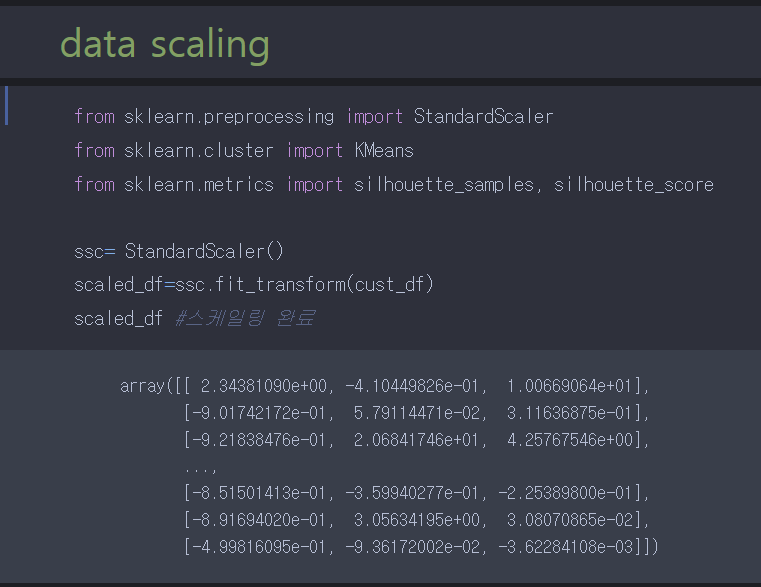
StandardScaler를 이용하여 표준화를 진행 시킬 것이고, 나중에 쓰일 군집 평가 실루엣 스코어와 kmeans를 부른다.
이후 fit_transform을 이용하여 데이터를 변환 한다.
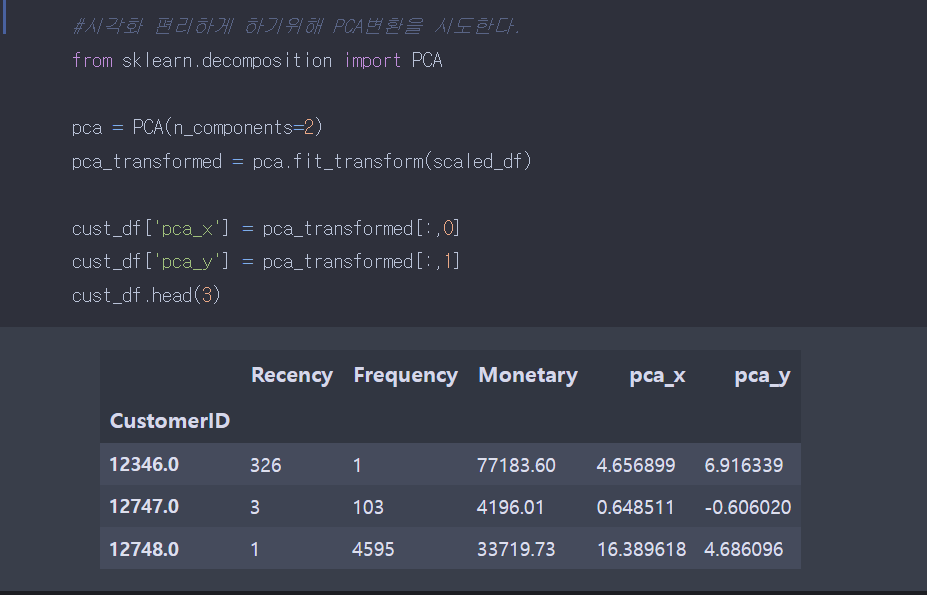
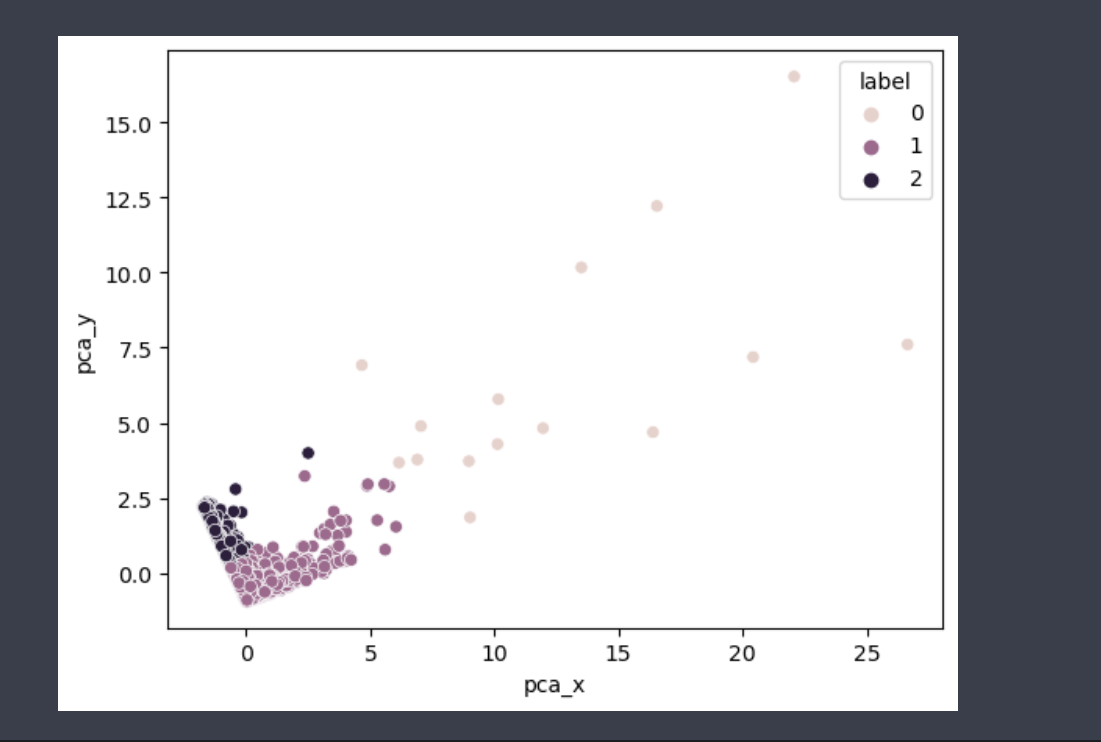
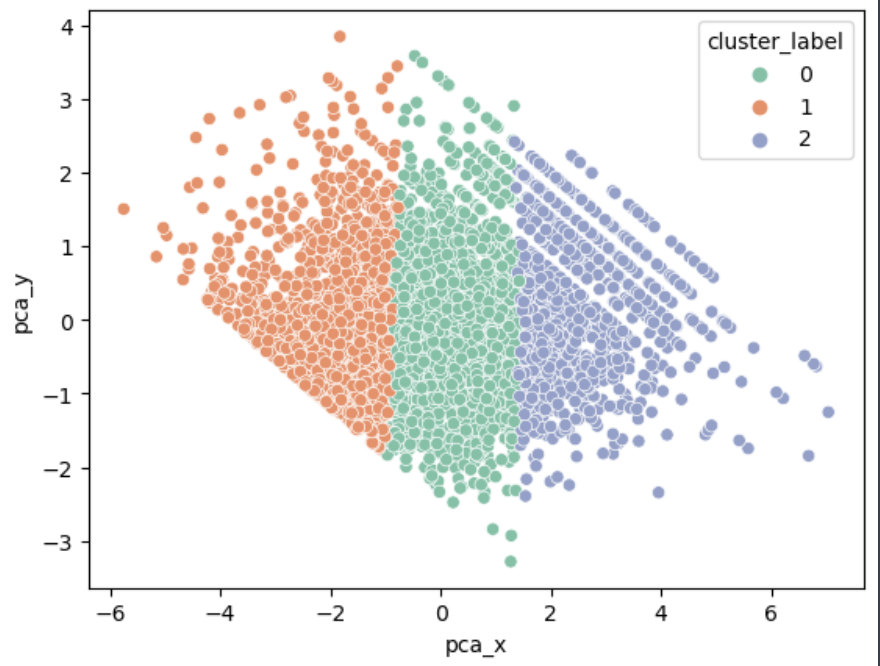
산포도를 확인하고 싶어서 PCA 변환을 이용했다. PCA 변환이 다중 공산성을 막아주는 장점도 있지만, 2차원이나 3차원으로 표현 가능해 시각화가 쉽다는 장점도 있다.

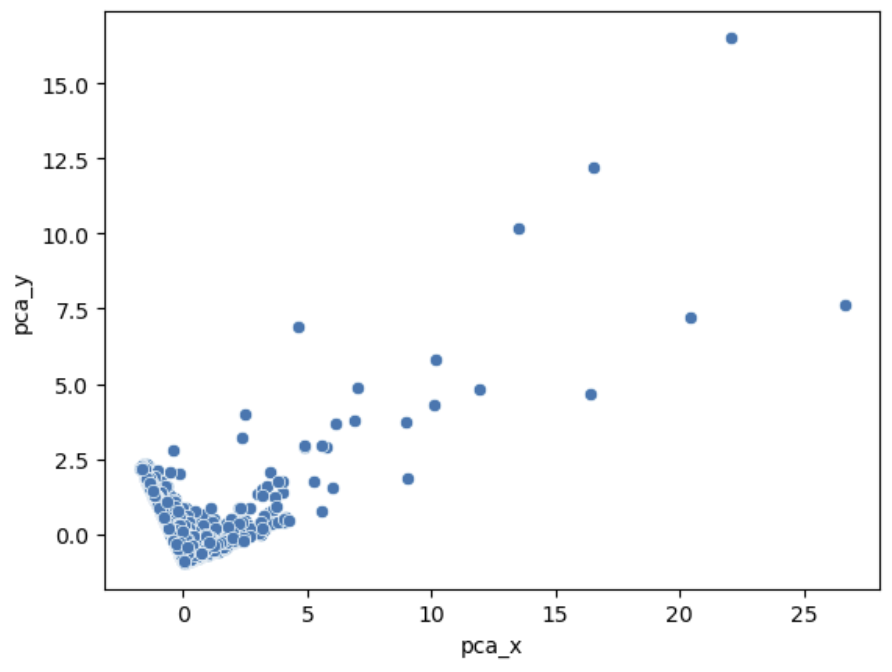
X, Y를 갖고 산포도를 비교하게 된 이유는 뭐냐면
1. 자료의 이상치나 흩어진 정도 보고 싶었음
2. X, Y가 둘다 연속 값일때는 점 찍는 방식으로 보는 것이 편함
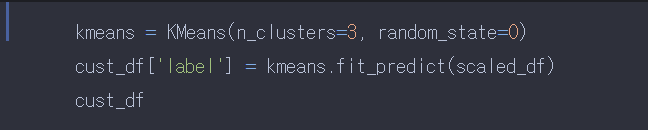
자야겠다..
'Python > 코딩 실습' 카테고리의 다른 글
| 결측치 leakage 없이 트리 예측 모델로 보간 (MICE 보간 사용 X) (1) | 2023.10.30 |
|---|---|
| 데이콘 기본 ML 대회에서 알게 된 것들 (왕초보편) (2) | 2023.10.06 |
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |
| [1일 1 캐글] Default of Credit Card Clients Dataset, PCA 이용 (0) | 2023.05.31 |
| 1일 1 캐글 프로젝트 시작(feat. 머신러닝) (0) | 2023.05.29 |