
얼마 전 범준이형과 함께 HD 현대 AI Challenge 대회에 나갔다.
초반에는 열심히 했지만, 후반에 여러 이슈들이 많아서 일주일동안 전혀 집중하지 못했다.
그래도 대회를 준비하는 과정 중 새롭게 알게 된 방식들이 많아 몇가지 작성한다.
*수정
의료 데이터 셋 대회에서 알게 되었는데,

이미 사이킷런에 결측치들 쉽게 학습시키고 예측값으로 보간하는 방법이 있었음;;
MICE 보간이라고 (나는 몰랐지.. )
CF. 참고 하세요 (MICE 보간)
MICE imputation - How to predict missing values using machine learning in Python - Machine Learning Plus
MICE Imputation, short for 'Multiple Imputation by Chained Equation' is an advanced missing data imputation technique that uses multiple iterations of Machine Learning model training to predict the missing values using known values from other features in t
www.machinelearningplus.com
하지만 나는 내가 함수를 사용해서 직접 논리로 수기 코드를 짰다..
조금 복잡해보여도 내가 한 생각들은 분명 의미있다고 생각한다.
(많이 복잡하다.)
구성
- 데이터 셋 결측치 탐색
- 예측 모델 함수
- 시각화로 차이 비교
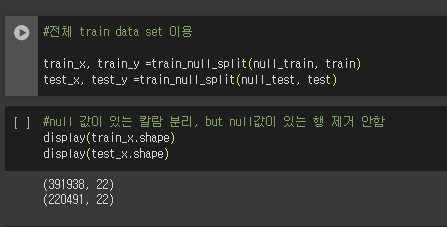
| 데이터 셋 결측치 탐색 |

391939 rows × 23 columns
데이터가 약 39만장이고, 컬럼도 23개이다.

결측 값의 수
BREADTH, DEPTH, DRAUGHT, LENGTH: 1개
U_WIND, V_WIND, AIR_TEMPERATURE, BN: 약 16만개
결측치가 1개인 칼람의 행들은 삭제하고, 16만개는 채워주는 방식이 필요해 보인다.
-> 결측 값 1개 탐색( BREADTH, DEPTH, DRAUGHT, LENGTH )

보니까 결측값이 1인 칼람들의 값은 하나의 행으로 합쳐진다. 이정도는 39만 데이터 중 날려도 될거 같다.

-> 결측 값 16만개 탐색( U_WIND, V_WIND, AIR_TEMPERATURE, BN )

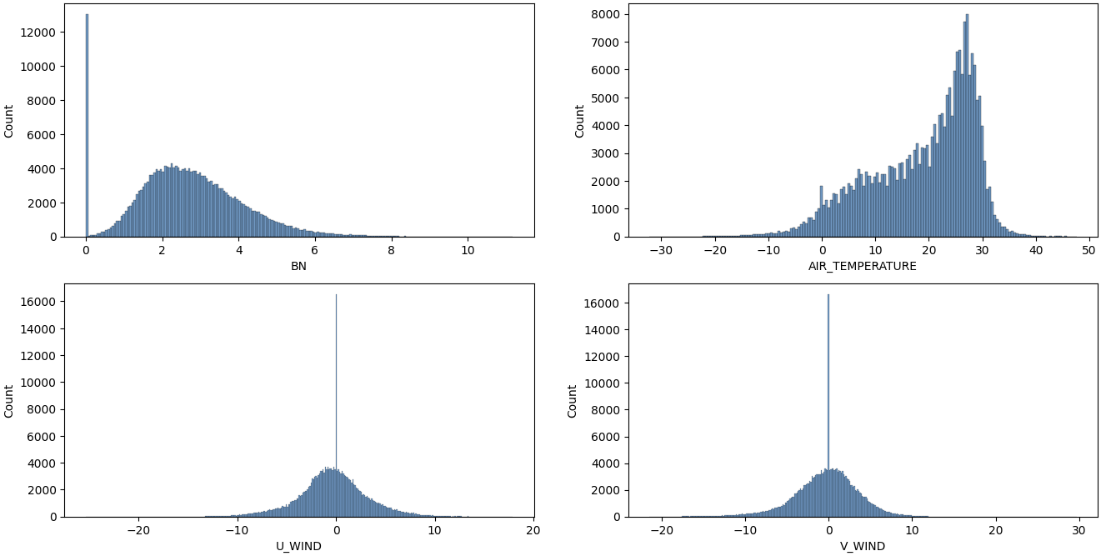
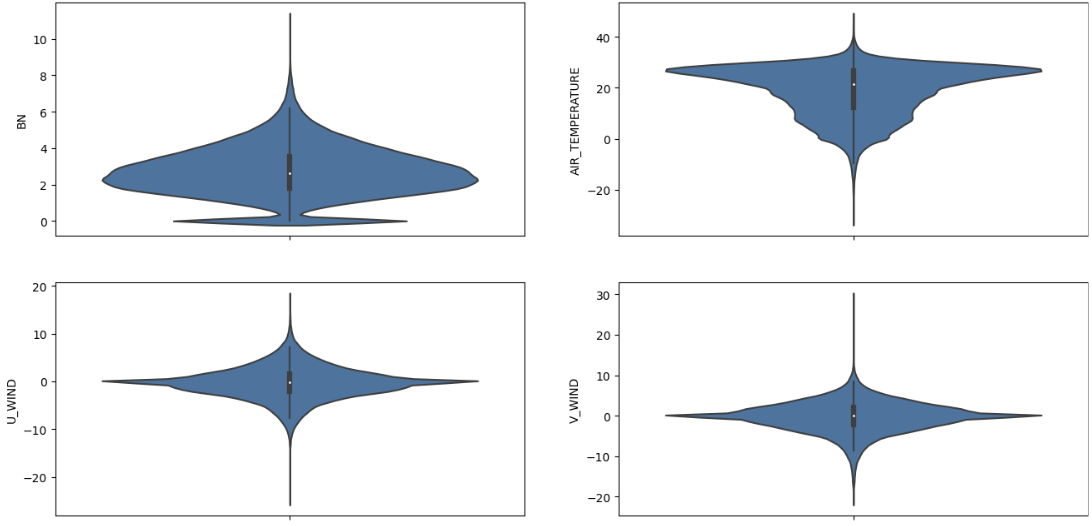
결측값들을 제외한 분포를 살펴보면 분포가 괜찮은 것을 알 수 있다.
| 예측 모델 함수 코드 |
결측치를 그럼 어떻게 처리할까?
1. 보통 결측치가 60프로 이상이면 칼럼 자체를 버린다. (Drop)
-> 390,000건 중 160,000이기 때문에 아쉽지만 칼람 삭제시 성능 저하 우려.
2. null값을 제외한 mean으로 대체한다.
-> 문제 발생 가능성. 평균의 저주.. 160,000건의 데이터가 평균값을 만들어 짐. 되려 학습 저하 가능
3. 결측치 16만건인 4개의 열을 모두 예측값으로 두고, train 데이터에 나머지 칼람을 이용하여 학습한 후, 결측값을 예측값으로 보간, 이 학습 모델을 test에도 이용
-> 데이터 leakage 발생 x, 그리고 적절한 분포를 가져가면서 보간 시킬 수 있음
함수 설명
학습 코드
# xgb로 예측하는 데이터셋 만들어줌
def function(X_train, y_train):
xgb = XGBRegressor()
model = xgb.fit(X_train, y_train)
return model
이건 단순함. 그냥 xgb트리 모델을 이용하여 학습을 할 수 있게 짜놓은 코드이다. (범주형 데이터가 많아 회귀보다, xgb 이용)
nan이 있는 칼럼만 뽑아주는 역할을 하는 함수
#nan칼람 뽑아주는 역할을 하는것
null_train = pd.DataFrame(train.isna().sum(), columns= ['nan'])
null_test = pd.DataFrame(test.isna().sum(), columns = ['nan'])#what null_train?
display(null_train) #이런식으로 nan이 있는 칼람들만 index로 뽑게
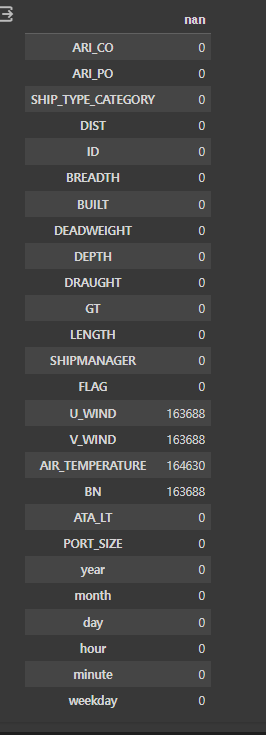
데이터 leakage가 걱정돼서, 이런 코드를 짜게 됐다.
(train에 있는 null값을 가진 칼람과 test에 있는 null값을 가진 칼람이 다를 수 있음. 무시하고 test에 있는 null값 기준으로 코드 짜면 leakage 발생)
#null이 있는 칼람 제외 X, Y 분리해서 뽑아줌
def null_find(null_df, df): #null_df와 , 그냥 df ex(train, test)
null_list = list(null_df[null_df['nan'] > 0].index) #null값이 있는 칼람의 이름 뽑기
nan_df = df.dropna(axis = 0) #dropna로 결측치 하나라도 있으면 삭제했음.
X = nan_df.drop(null_list, axis = 1)
Y = nan_df[null_list]
return X, Y
#X: null이 없는 칼람 학습용, Y: null값만 뽑기
위에서 null값이 없으면 0, 있으면 null값의 숫자로 표현되는 것을 볼 수 있다.
그것을 기준으로 X는 null값이 있는 칼럼을 제외한 학습 데이터, Y는 null값을 가진 열로 구성했다.
근데 문제가 Y의 같은 경우 4개의 열로 구성된다.
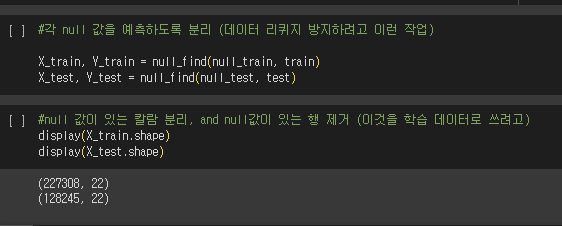
#학습 할때 그냥 null값 분류해주는 것
def train_null_split(null_df, df): #null_df와 , 그냥 df(train, test)
null_list = list(null_df[null_df['nan'] > 0].index) #null값이 있는 칼람의 이름 뽑기
X = df.drop(null_list, axis = 1)
Y = df[null_list]
return X, Y #얘는 대신 전이랑 다르게 null값이 있는 행들도 뽑아줌
위의 코드와 유사하지만, 이 코드는 null값을 지닌 행을 삭제하지 않는다.
결측값 보간
(다시봐도 내가 코드를 너무 더럽게 짰음.. 마땅한 방법이 생각 안나서 그랬습니다..)
#함수 생성 nan xgb regression으로 채워주는 함수
def model_null_pred(X_train, Y_train, X_test, Y_test, train_x, test_x, train_y, test_y, train, test): #train_df, test_df는 전체 데이터 셋 넣는것
if (sum(Y_train.columns != Y_test.columns) > 0) or (Y_train.shape[1] != Y_test.shape[1]): #train과 test에 결측치 있는 칼람이 다를 경우
return train.fillna(train.mean(), inplace=True), test.fillna(train.mean(), inplace=True) #그냥 train 평균값으로 채우기
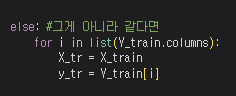
else: #그게 아니라 같다면
for i in list(Y_train.columns):
X_tr = X_train
y_tr = Y_train[i]
model = function(X_tr, y_tr) #데이터 lekage예방 train 데이터만 활용
pred_train = model.predict(train_x)
pred_test = model.predict(test_x)
train[i] = np.where(train[i].isnull(),
pd.Series(pred_train.flatten()),
train[i]) # train 칼람 하나씩 null 값 대체
test[i] = np.where(test[i].isnull(),
pd.Series(pred_test.flatten()),
test[i]) # train 칼람 하나씩 null 값 대체
return train, test
함수를 보면 if와 elif로 구성된 것을 볼 수 있다.
if는 쉽게 말해, train과 test의 결측치 칼람이 다를경우를 말하는 코드이다.
그렇게 되면, 학습을 진행하지말고 train 평균값을 이용하여 보간하라는 코드이다.
if 살펴 보기
(numpy의 불린 인덱싱 트릭을 이용하여 구성)
true : 1
false: 0 이다.
트레인과 테스트 칼람이 같지 않다면 sum시, 주어진 수식은 True로 1이상이다. 따라서 칼람의 종류가 같지 않은 경우를 따지기 위해 작성했다.
뒤의 부분은 shape이 같지 않은 경우를 고려하여 작성했다. 같은 칼람을 갖고 있어도 train에는 4개의 칼람, test에는 3개의 칼람만을 가질 수도 있다.
elif 살펴보기
이건 train과 test의 결측치 칼람이 같을 때를 다룬다.
먼저 주의 해야할 사항이 결측치 칼람이 여기선 4개였다.
xgb모델은 4개의 열에 대한 예측값을 반환하지 않는다.
따라서 for문을 통해 하나씩 학습하고 결측값을 채워주도록 구성했다.

이후 np.where을 이용했다. 즉, 예측값을 반환하면 약 390,000건에 대한 예측값을 반환한다. 그중 우리가 필요한 것은 결측치가 있는 160,000건의 데이터만 보간해주면 된다.
즉, train[i]의 시리즈의 원소가 null이면, 그때 예측값으로 보간을 하란 뜻의 코드이다.
적용했을 때
train, test =model_null_pred(X_train, Y_train, X_test, Y_test, train_x,test_x, train_y, test_y, train, test)
#와 미친 해냈다....
display(train.isna().sum())
display(test.isna().sum())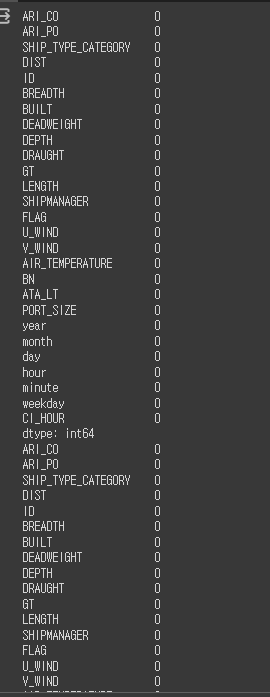
| 시각화로 차이 비교 |
평균 값으로 결측값 보간 시 분포
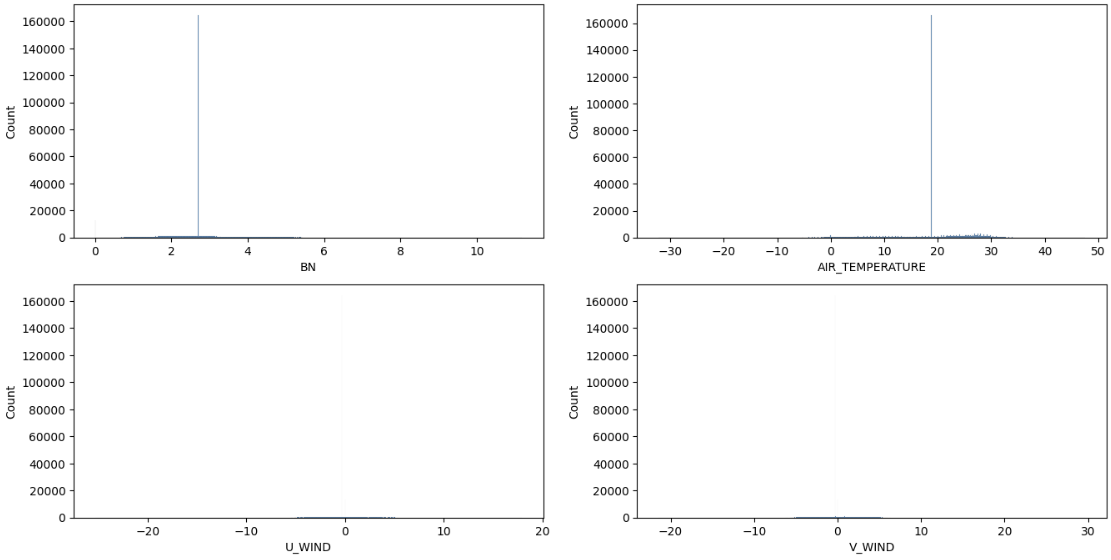
내가 만든 함수 사용시
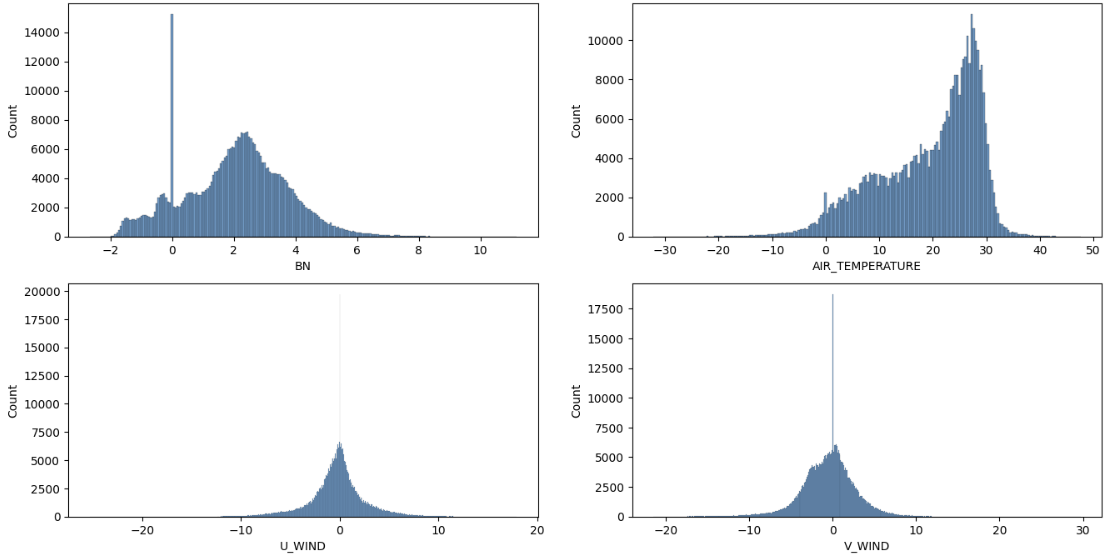
null값을 제외한 분포와 크게 차이가 없는 것을 확인할 수 있음.
지렸다 이관형 ~
'Python > 코딩 실습' 카테고리의 다른 글
| Samsung AI Challenge: Black-box Optimization (1) | 2025.04.07 |
|---|---|
| 시계열은 처음이라 (제주도 특산물 가격 예측 AI 경진 대회) (3) | 2023.11.21 |
| 데이콘 기본 ML 대회에서 알게 된 것들 (왕초보편) (2) | 2023.10.06 |
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |