쌓인 업보들을 청산하는게 참 힘드네요. 이번 글은 2024.08에 참여한 경진 대회
'Samsung AI Challenge 반도체 Black-box Optimiztion' 에 관한 내용을 담으려고 합니다.
저희는 3명이서 팀을 꾸려서 나갔고 최종적으로 상위 7프로의 성과를 거두었습니다.

00 | 대회 소개

알고리즘 | 채용 | 정형 | 최적화 | Recall
주제 :Black-box Optimization 반도체 공정 설비와 반도체 공정 파라미터 미세 조정 → 기존의 지식으로는 부족
cf. what black box?
공정의 복잡성과 비밀성 때문에 내부 작동 원리를 완전히 이해하기 어려운 상황을 설명할 때 사용.
즉, 공정의 입력과 출력은 알 수 있지만, 그 사이의 내부 과정이나 원리를 명확히 파악하기 어려운 경우를 의미.
최종 목적 : 데이터 분포와 최적화된 파라미터 사이의 균형점을 잘 찾는 것이 중요
00 | Data set
Data Set 요약TrainTest


| Shape | 40118 × 12 | 4986 × 11 |
| dtype | float64 12개 | float64 11개 |
| 특성 | x_0 ~ x_10 (센서) + y | x_0 ~ x_10 |
데이터에 대한 상세 설명은 대회에서 주어지지 않음.
삼성전자 반도체 대회니 y는 산출량으로 보고, x 값은 센서나 재료 등으로 파악 됨
데이터는 기기 설정값을 녹화한 시계열로 보임
x_feature: 공정에서 발생하는 센서 데이터 (여러 공정 데이터)
y_feature: 예측해야할 target 값
00 | 특이 사항
- test data를 통해 얻을 수 있는 것은 예측값.
- but, 평가 지표는 이진 분류에서 사용되는 recall 값임.


📝 Idea
- Test 예측값 상위 10 % 추출
- 대회 측이 보유한 정답 상위 5 % 추출
- 교집합의 비율 → Recall = TP / (TP + FN) ➡️ 상위 구간을 놓치면 점수 0!
➡️ 모델링 목표 : Top 10 %를 얼마나 정확히 잡아내느냐
00 | 분석 전 데이터만 보면 ?

아무래도, 센서치를 시간 순서대로 찍었다는 가정하에 1D CNN을 적용한 모델이 성능은 가장 괜찮게 나왔음
01 | 문제정의 (EDA)
EDA ① Target(y)

- 첨도 심함 : 82 ~ 84에 밀집
- 왜도 심함 → 정규성 미충족
- log1p 변환으로 분포 완화
- 상위 25 % → 1 / 나머지 0 이진 레이블 변환 → Recall 최적화 학습 (Class 불균형 가능)
EDA ② 연속형 피처(x)
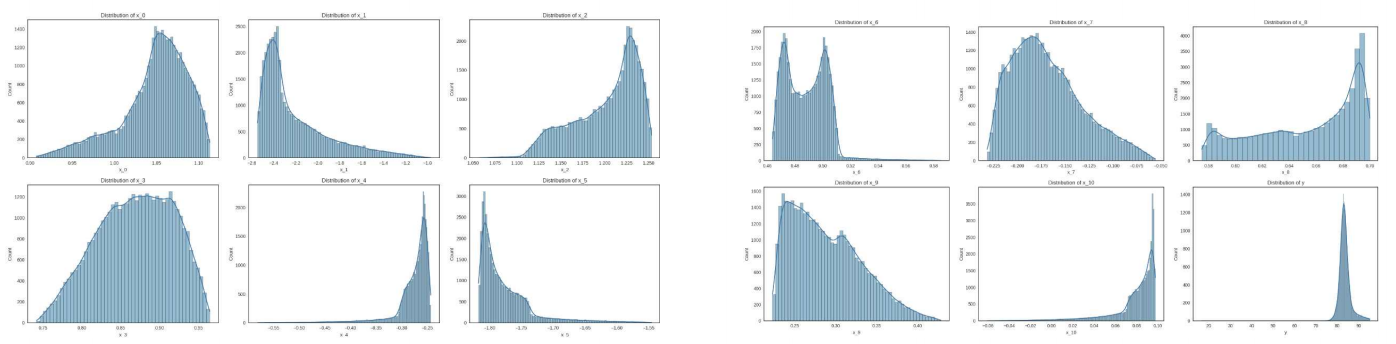
- 데이터 분포가 일정적 : 시간 순서대로 발생하는 센서 값을 찍었을 가능성이 있음 (시계열적 방법론 가능)
- 모두 float 형태 → ML모델로 회귀 모형을 사용하게 되면, 다양한 분포를 가져갈 수 있는 방법론이 중요함. (Hypothesis space를 넓히기 위해)
- 표준화: 회귀 모형의 가정 (정규성, 독립성, 등분산성) -> Z- score로 변환해서 정규성을 만족 시켜야함
연속형 피처(x와 y의 관계)
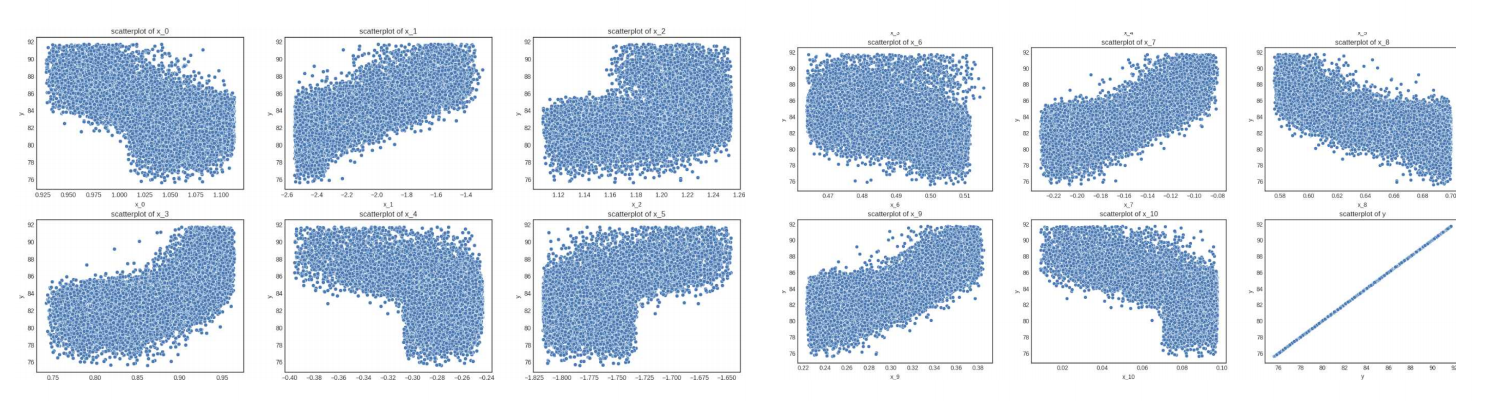
- 문제 :
- x와 y의 선형성이 돋보임
- 상위 10프로의 값을 예측하기 위해 데이터 resampling이 필요
- 선형성을 이용할 수 있는 방법론
연속형 피처(x의 상관 관계)
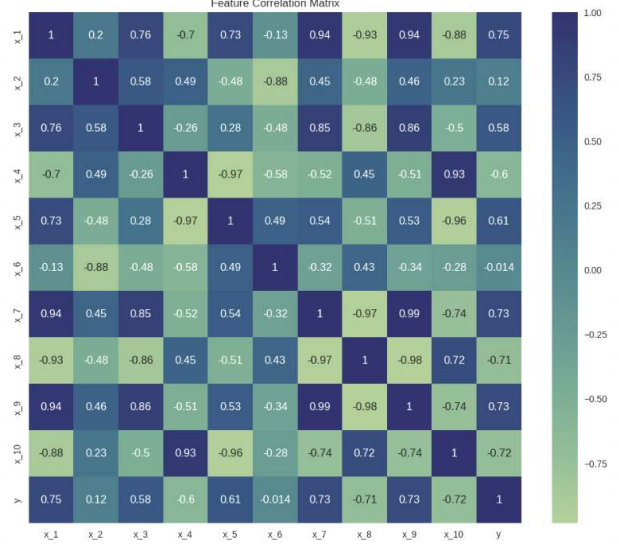
- 문제 :
- 상관계수가 높음 -> 각 feature 간의 독립성을 부여하는 방식이 중요.회귀 모형 사용시, 다중 공선성을 주의해야 함. (각 모델에 가정에서 벗어남. 독립이 아니라면) (이건 내 주관인데, 회귀 모형을 사용할 것이 아니라 트리계열 모형을 사용할 땐 상관계수는 굳이 보지 않는 편)
문제 요약 – Pain Points

추가 작성 중....
SLIDE 7 | EDA ③ 이상치 & 노이즈
- 3σ 밖 데이터 ≈ 2.9 %
- 센서 스파이크 존재
📝 Idea
- Denoising : EMA(α 0.3)
- Outlier → NaN → Spline 보간
- 결측치 : 소량 → 선형 보간
SLIDE 8 | 문제 요약 – Pain Points
- Target 첨도 → 상위 구간 예측 필수
- 피처 상관성 → 모델 불안정
- 센서 노이즈 & 이상치 → 미세 패턴 손실 가능
SLIDE 9 | 문제 해결 – 전처리 파이프라인
① Noise Filtering : EMA
② Outlier Removal : 3σ → NaN → Spline
③ Target Transform : log1p / binarize(top25%)
④ Resampling : SMOTE(k=5)
⑤ Feature Eng. : Fourier(week,month) + Holidays + Poly + PCASLIDE 10 | 모델 후보군
| 분류 | 모델 | 목적 |
| 회귀 | XGBoost · LightGBM | 수치 피처 + 상호작용 자동 학습 |
| 시계열 | DLinear · Prophet | Trend & Seasonality 반영 |
| 딥러닝 | 1D CNN | 센서 패턴 캡처 |
| AutoML | PyCaret · AutoGluon | 빠른 탐색 & 스태킹 |
SLIDE 11 | 1D CNN 아키텍처
Conv1D(64, k3) → Conv1D(128, k3) → GAP → Dense(256) → Dense(1)
- LR 1e‑3, Cosine Annealing
- Deep / Mid / Shallow 3 버전 학습
SLIDE 12 | 앙상블 전략
Pred_final = 0.4·CNN_deep + 0.3·LGBM + 0.3·AutoGluon
- Soft Voting → 연속 예측
- Top 10 % 컷오프 → Recall 계산
SLIDE 13 | 결과
| Recall(Public) | Recall(Private) | |
| 기존 베이스라인 | 0.62 | 0.59 |
| 제안 방법 | 0.812 | 0.794 |
→ +17 %p 개선, 최종 상위 10 % 달성
SLIDE 14 | 추가로 하려던 것
- AutoML 앙상블 : 센서별 AutoGluon 후 메타‑앙상블
- 도메인 지식 : 공정 물리 조건 반영 피처
- 다양한 딥러닝 : Transformer‑TS, WaveNet 등 시도 예정
SLIDE 15 | 인사이트 & 다음 단계
- 상위 구간 전용 전처리 + Recall 지향 모델링 이 핵심
- 1D CNN + Resampling으로 Black‑box 공정도 데이터만으로 최적화 가능
- 향후 Bayesian Optimization + MLOps 파이프라인으로 실제 공정 적용 예정
'Python > 코딩 실습' 카테고리의 다른 글
| 시계열은 처음이라 (제주도 특산물 가격 예측 AI 경진 대회) (3) | 2023.11.21 |
|---|---|
| 결측치 leakage 없이 트리 예측 모델로 보간 (MICE 보간 사용 X) (1) | 2023.10.30 |
| 데이콘 기본 ML 대회에서 알게 된 것들 (왕초보편) (2) | 2023.10.06 |
| [1일 1 캐글] 군집화 실습 - Customer Segmentation(with 파이썬 머신러닝 완벽가이드) (0) | 2023.06.08 |
| [1일 1 캐글] 당뇨병 위험 분류 예측 경진대회(데이콘) EDA 분석 part1 (0) | 2023.06.02 |