서론: 학기 중에 따로 딥러닝 이론과 심층 구현 공부할 시간을 내기가 정말 힘듭니다.
따로 공부할 시간을 내기 힘들거 같아서, 현재는 공모전과 프로젝트(보아즈 ADV)만 진행 중이고 , 완료되면 티스토리에 작성할게요..
일단 데이터와 관련된 내용이니 보고서라도 하나 작성해봅니다. (python으로 구현해서 품.)
2주차 보고서 주제

공분산, 상관계수?
공분산과 상관계수가 무엇인지 먼저 알아야한다.
[1일 1 캐글] Default of Credit Card Clients Dataset, PCA 이용
1일 1 캐글 프로젝트 첫 날이다. 첫날은 간단한 것부터 시작하려고 한다. 위의 데이터에서 상관 분석을 통해 상관 관계를 시각화 하고, 그것을 바탕으로 상관도가 높은 부분은 PCA분석으로 차원을
hyeong1197.tistory.com
내가 예전에 작성한 글 참고 (이 부분 정리해 놓음.)
+ 추가적으로 데이터 마이닝 시간에 학습한 것
분산과 공분산?
분산은 한 변수 내 (x), 공분산은 두 변수 이상 퍼짐 정도나 연관성 나타냄 (x, y)
-> 통계학개론 공부할 때, 분산은 한 데이터 내부에서 퍼짐 정도 공분산은 2개의 엑셀 데이터 비교할때 사용했음.2개 이상의 데이터 (엑셀 표) 주어지면, 그것의 퍼짐 정도를 확인하기 힘드니, 공분산 이용하는 듯
표준 편차 (모분산)
n-1로 나누는 이유가 모분산의 표준 편차를 구하려는 의도인지 처음 알았다.
파이썬에는 모분산 표준편차를 나타내는 함수가 없어서, 처음에 값이 다르게 나왔지만 현재는 수정함.
파이썬 (주제 하나씩 구현)
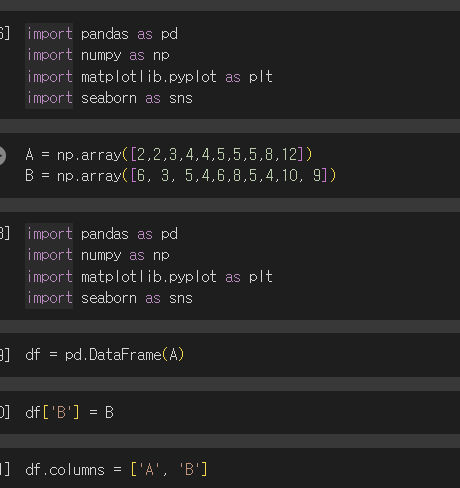
각 load와 데이터 값을 array로 채워주고 dataframe을 만들었음.
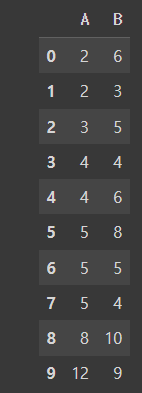
- 데이터
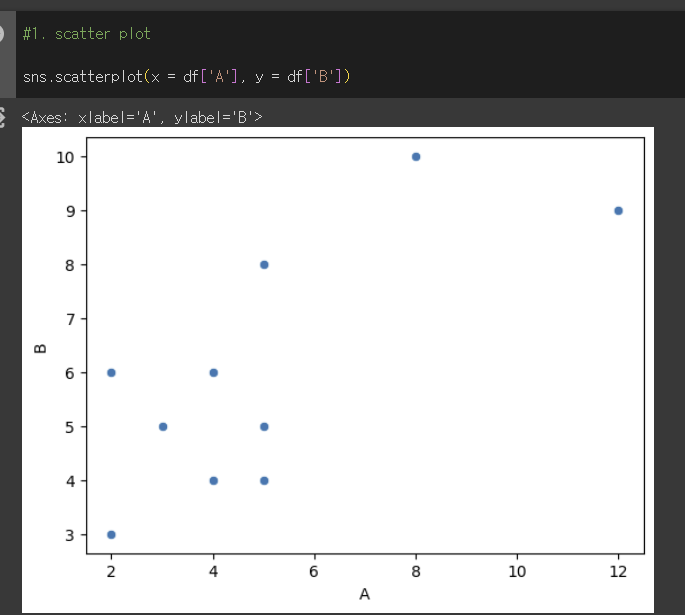
- scatter plot 그리시오
- A,B에 대한 공분산과 상관계수를 계산하시오. (편차 n-1로 나눴을때 값인지는 모르겠음) → 해결

이게 소수점이 너무 길어지니, 값이 작아지면 0 이나 inf가 떠서 진짜 짜증났음.
평균 값이 정수로 나오는 듯 해서 굳이, float형 자료구조를 사용할 필요가 없다고 느낌.
int로 바꿔주니 문제 해결 됨.
표준편차
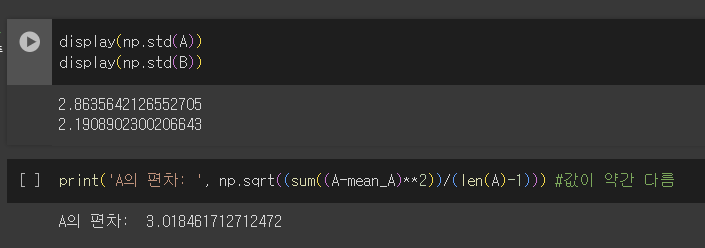
처음엔, 단순 표준편차 구하는 함수 사용하려고 하는데, 직접 구하는 표준편차와 약간의 차이 발생
-> 내 생각: 기존 표준편차 구하는 공식은, 모분산 표준편차가 아님. 그래서 값이 다른 듯

- 두 변수 A와 B에 대한 공분산과 상관계수를 계산하시오


2. Z-Score 방법을 이용하여 표준화한 후 수행
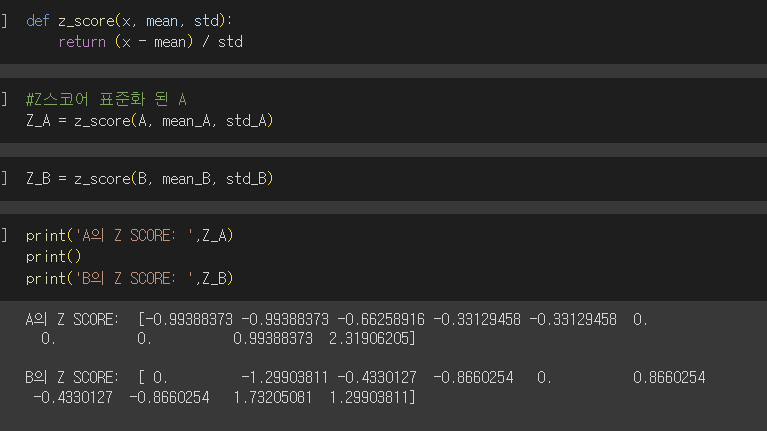
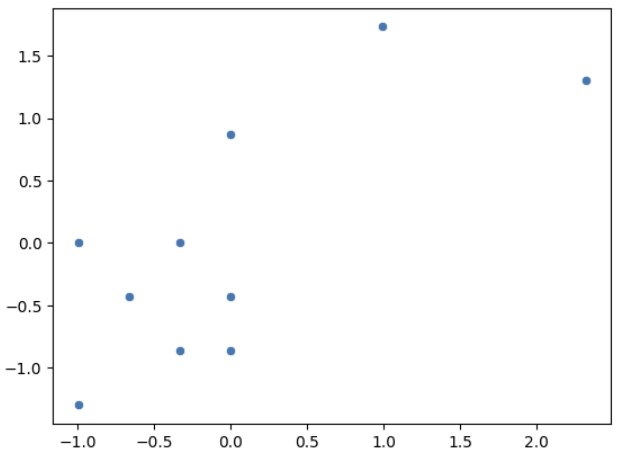
- 데이터 scatter plot을 그리시오
- 두 변수 A와 B에 대한 공분산과 상관계수를 계산하시오

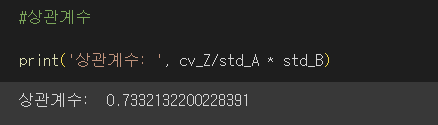
-> 양의 상관관계, 공분산과 상관계수가 동일하다.
3. 표준화 전후 Scatter plot 상 차이점을 기술하시오.
→표준화 이후 평균이 0, 표준편차가 1인 분포를 갖게됨. (범위가 달라짐)
4.표준화 전후 공분산과 상관계수 관계의 차이점과 그 이유를 기술하시오.
공분산 / 각표준편차의 곱: 상관계수 (공분산 표준화)
공분산은 크기만 나타냄, 정도를 따질수 없다.
z-square로 변환과 동시에 표준편차는 1이되니
변환 후 공분산 = 상관계수가 됨.