이번 시간에는 대표적인 cv 알고리즘인 CNN에 대하여 설명할 것이다. 최근에 보아즈 멘토 멘티 수업 중 vgg paper내용이 끝난 후, 함께 정리할겸 글을 작성해 보았다.
기초적인 내용들은 이미 충분한 자료가 많으니, 다루지 않을 것이고, 학습할때 한번쯤 지나쳤을만한 내용들을 위주로 설명을 하겠다. 먼저 목차부터 보자.
목차
- CNN의 기본 구성
- Convolution의 이해(receptive field, feature maps)
- max pooling
- FC layers(완전 연결망)
이렇게 구분할 수 있다.
| CNN의 기본 구성 |
CNN이전 ANN(Artificial neural network)부터 복습을 해보자.
ANN: 가장 기본적인 인공 신경망이다.

나의 티스토리 글에 있는 내용 대부분이 이러한 인공 신경망 (모든 레이어에서 깊은 학습)이다.
구성: Affine ,Activate Function(ReLU)
기본적인 구성은 Affine(가중합과 편향의 계산), 활성화 함수(ReLU)이다.
그렇다면 CNN은 무엇인가? 왜 이미지, 음성 처리시 CNN을 사용하는 것일까?
천천히 알아보자.
먼저 CNN을 사용하는 이유부터 살펴 보자.
이유는 3가지 정도로 분류 할 수 있다.
1. 이미지, 음성 데이터 처리시 성능 향상
2. 과적합 방지
3. 이미지의 공간 정보를 유지한채 학습
MNIST데이터 셋을 공부하면 알 수 있듯이, 3차원 이상의 데이터를 1차원으로 flatten후 학습시키면, 이미지의 개념이 날라간다. 즉, 공간상의 개념이 날라간다. 또한 작은 이미지의 변형(픽셀값의 변화, 이미지 일부 손상)에 취약하다는 단점이 있다. 깊은 신경망으로 학습을 진행하다보면 학습 데이터에 취중한 과적합이 발생할 수 있지만, convolution과 max pooling으로 핵심정보는 추출 하면서, 연산속도와 과적합을 방지할 수 있다.(flatten시 1차원으로 변형, 이것은 2차원 공간상의 정보를 잃기 때문에 train에만 맞는 데이터로 학습이 된다.)
CNN: Conbolutional Neural Network
이미지 등을 처리할 때 가장 기본적인 개념이다. 기존 신경망에서 convolution과 pooling의 개념이 추가 된다.
위의 사진과 같이 input 이미지 데이터가 들어오면, convolution과 pooling과정을 수차례 반복하고, 이후 classification을 진행한다. 이때 Affine, 활성화 함수의 과정이 시행된다.
구성: Feature learning(conv + Activate Function(ReLU) + Max pooling), Classification(Affine ,Activate Function(ReLU))
CNN은 기본적으로 두 가지 방식으로 진행된다.
첫째, Feature learning
피처를 학습한다. 이때 공간정보를 유지하기 위해 convolution과 pooling을 수차례 반복하는 과정을 갖는다.
(convolution과 pool은 추후에 다시 설명)
이후 둘째, Classification
1차원으로 flatten후 기본 딥러닝 신경망 학습을 진행한다.
Affine + 활성화 함수
| Convolution의 이해 |
그렇다면 convolution이 무엇일까? 기본 개념은 이미 알고 있다는 가정하에 빠르고 보고 넘어가자.
밑에 그림은 위의 말 이미지를 conv하는 과정이다. 이미지는 행렬이기 때문에 특정 숫자 값을 갖는다. 위의 말 이미지 한장을 행렬로 나타낸 그림이 밑에 그림이라고 가정하자.
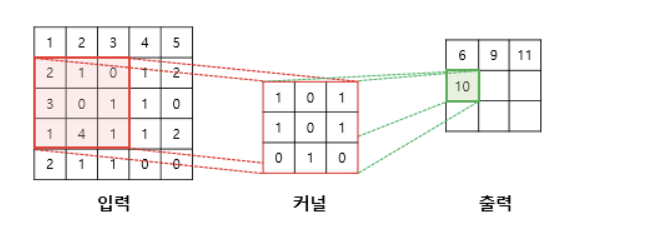
이렇듯 입력 이미지 2차원 배열에 커널이 각 자리수의 곱을 통해 하나의 정보로 축약한다.
즉, convolution을 진행시 공간상의 정보를 하나의 픽셀로 축약가능하다.
위의 경우는 3*3의 정보를 10이라는 하나의 픽셀로 축약한 것이다.
자세한 내용은 유튜브나 구글링 참고
그렇다면 이러한 컨볼루션을 왜 사용하는 것일까?
convolution을 사용하면, 이미지 한장 당 각각의 특성을 추출할 수 있다.
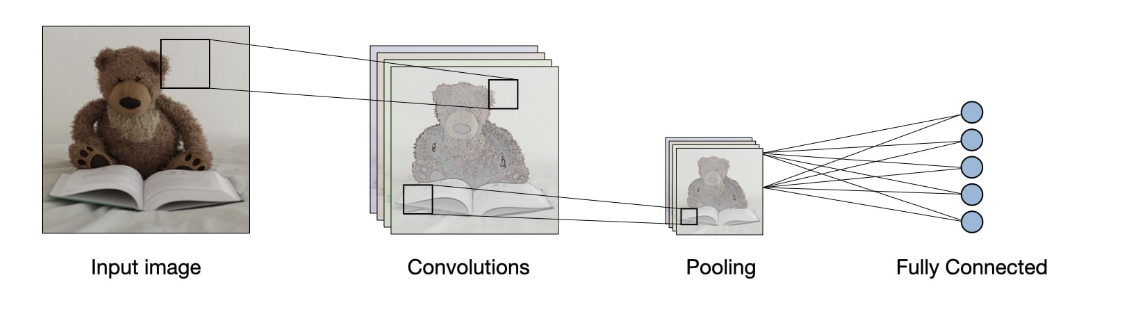
이는 사람의 눈을 참고하여 만들었는데, 사람이 물체를 인식할 때, 전체를 다 보는 것이 아니라 일부씩 나눠서 본다.
(예시로 곰인형을 볼때는 귀의 모양은 둥근 edge, 귀의 코는 검정색 타원 등 이러한 정보를 종합하여 판단하게 된다.)
이처럼 컨볼루션을 사용하면 여러가지 특성을 가진 feature maps들이 나오게 되고, 각각은 다른 특성을 갖게 된다.
이러한 과정이 가능한 이유는 conv연산안에 0이나 특정 값을 넣어 일부 픽셀의 값을 조정하여 특정 특성만 뽑아낼 수 있기 때문이다.
이러한 과정이 반복되면, 입력 사이즈에 비해 출력 사이즈가 줄어들 수 있다.
이것을 방지하기 위해 학습시 padding을 사용한다.
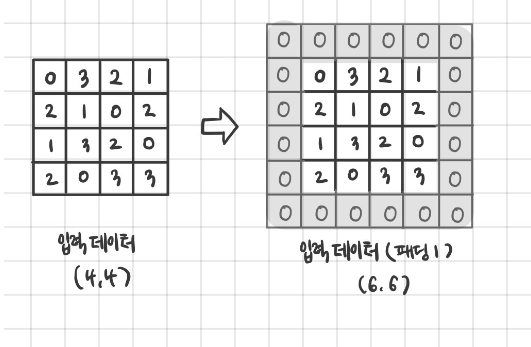
주로 zero padding을 사용한다. padding을 통해 convolution 연산 후에도 같은 이미지의 사이즈를 반환할 수 있도록 만든다.
| receptive field |
이제 receptive field에 대해 설명하겠다. 결론부터 말하면, conv연산을 반복 할수록 receptive field가 넓어진다.
receptive field 는 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기이다.
이미지를 보면서 이해를 해보자.
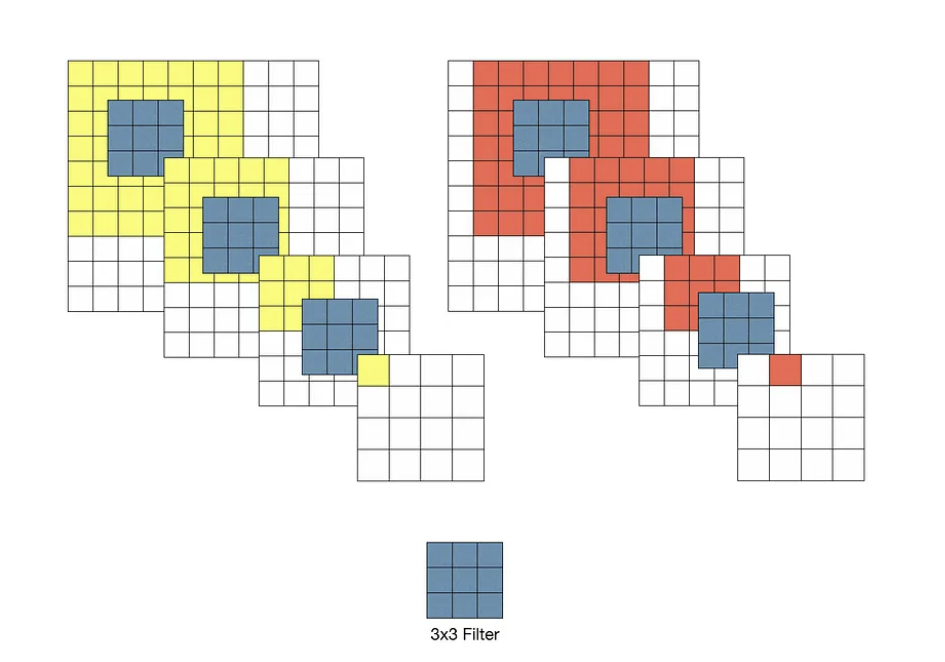
위의 예시에서 input의 데이터는 10*10인 이미지 데이터를 3*3필터로 convolution한 결과이다.
step 1: 첫번째 conv 이후 출력되는 데이터는 8*8데이터 행렬이다.
이때 1픽셀은 원본 이미지의 3*3의 이미지 정보를 담고 있다.
8*8이미지 행렬에 한번 더 conv를 진행하면 어떻게 될까
step2: 두번째 conv이후 출력되는 데이터는 6*6 데이터 행렬이다.
이것의 1픽셀은 8*8 데이터 행렬의 3*3의 공간정보를 담고 있다.
즉 10*10(원본 이미지)의 데이터의 5*5의 이미지 정보를 담고 있는 것이다.
...
이런 식으로 conv를 진행할 수록 한 픽셀당 담는 공간정보의 field는 늘어난다. 즉 receptive field는 convolution을 진행할 수록 늘어나는 방식이다. 더 많은 수용 범위를 확인할 수 있다.
| feature maps |
그렇다면 feature map은 어떻게 될까?
입력 이미지 한장의 커널 하나를 적용하면 출력 값이 하나 즉, feature map이 1가지가 나오는 것일까?
답은 그럴 수도 있다이다.
맨첨에 나도 이 개념이 헷갈렸는데, 그 이유는 우리가 2차원 데이터를 기준으로 이미지를 이해해서 그렇다.
먼저 필터와 커널의 개념의 차이를 이해해보자.
fiter vs kernel
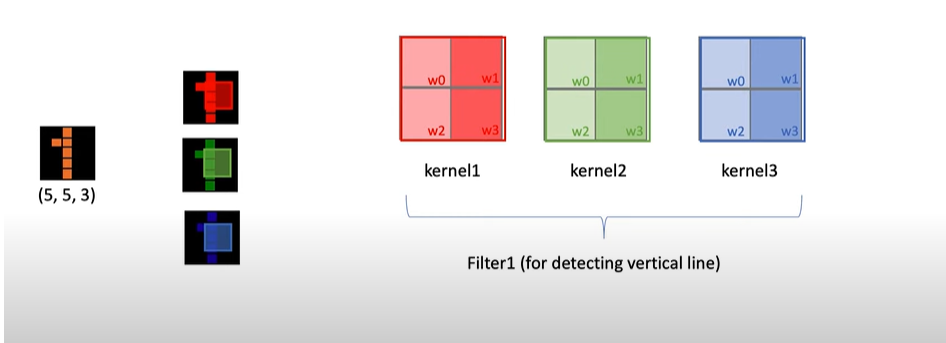
위의 이미지는 r,g,b 값을 포함한 이미지이다.
실제로 우리가 다루는 이미지는 3차원 이미지이다.
kernel: 각 2차원 이미지 데이터 한장당 적용하는 conv
Filer: 여러가지 커널이 존재, 한가지의 특성을 찾기위해 이미지의 개수만큼 커널을 갖고 있는다.
즉, convolution연산 시 2차원 한장 당 적용하는 것을 kernel, 각 이미지 만큼 이러한 커널의 수를 갖고 있는 것을 filter라고 한다.
위의 3차원 이미지 한장에 대한 conv연산 적용시 적용하는 kernel은 3개지만, filter는 1장이다.
출력되는 결과 값은 이러한 kernel에 (r,g,b)적용을 종합한 하나의 피처맵이 나오게 된다.
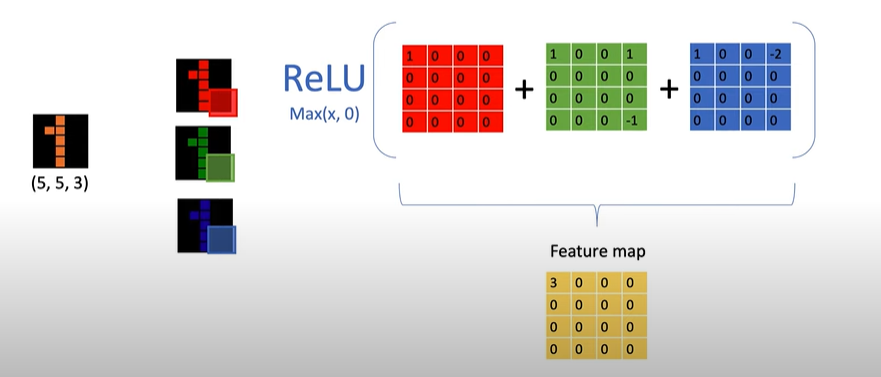
이런 결과 값을 갖는다. 출력된 r,g,b의 정보를 편향과 함께 더한 뒤(feature map) 활성화 함수를 처리한다.
즉, 3차원 정보에 kernel 수 만큼 피처맵이 만들어지는 것이 아니라, 필터의 수(3r,g,b값 축약)만큼 피처 맵이 만들어진다.
| pooling |
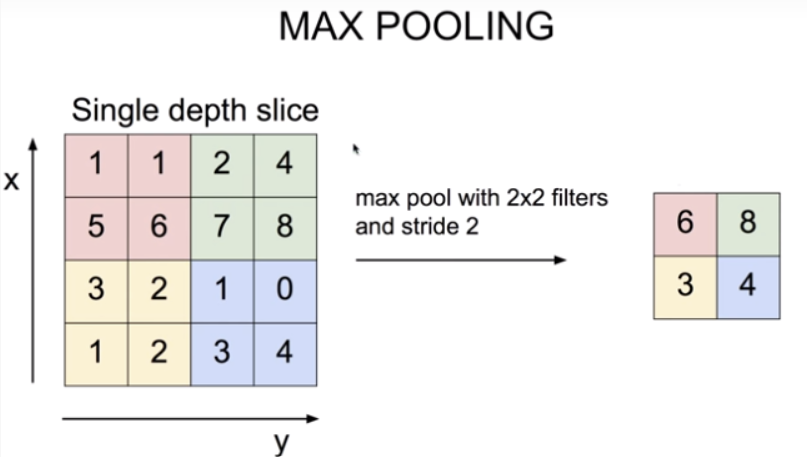
풀링에는 max, min, avg(평균)등 많은 방법이 있지만 max pooling을 기준으로 설명하겠다.
conv와 유사하게 각 행렬에서 최대값을 반환한 이미지 행렬을 만든다.
쉽게 sampling으로 이해하면 된다.
이러한 풀링은 공간을 줄이는 연산을 할 수 있기 때문에 한다. (중요한 특성은 유지하면서)
장점은
1. 매개 변수가 없다
2. 채널 수 변화가 없다.
3. 강건하다.
따로 학습의 연산이 들어가지 않기 때문에 매개 변수가 없다. 또한 입력 데이터의 변화가 되더라도 max값만 가져가기 때문에 강건하다.
| FC layer(fully connected neural network) |
완전 연결망이다. 앞에서 설명한 방식과 동일하다.
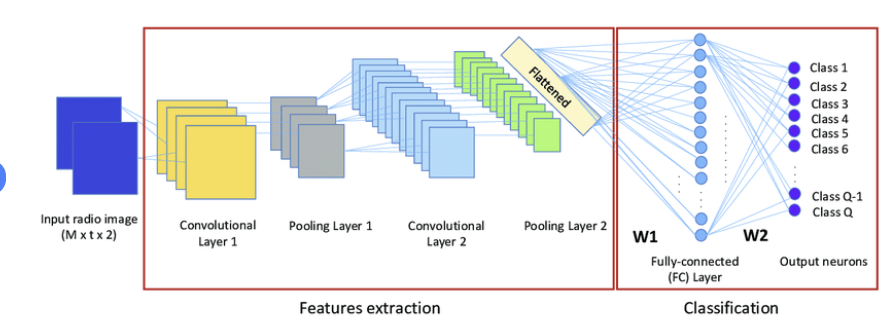
이제 분류를 시작한다. 이전 활성화 함수로 ReLU를 사용했던 것과 달리, 마지막 출력층 활성화 함수로 softmax를 사용한다.(확률값 반환)
지정한 class만큼 반환 값이 나오고 각 값의 합은 1이 된다.
마무리하며
이해한 점
1. vgg paper의 적용 방식과 CNN의 방식을 함께 공부하면서 각각의 피처맵이 어떻게 형성되는 지 이해할 수 있었다.
2. pooling의 연산의 이유와 conv연산을 왜 사용하는 지 알게 되었다.
3. 아직 CNN을 코드 구현 한적이 없지만, 코드를 어떻게 구성해야할 지 대략 예상이 간다.
질문
1. 각각의 학습 파라미터는 어떻게 구성되는지가 궁금하다.
2. 각 conv 행렬의 값은 파라미터와 같이 연산시 알아서 최적값을 찾아준다고 하는데, 어떤 원리로 찾아줄까 궁금하다.
3. 패딩을 통해 원본 사이즈는 유지하지만, 분명 원본 데이터에 손상이 갈텐데 과연 패딩을 통해 학습을 구현해도 될까?
출처:
유튜브 강의 자료
티스토리 글:
https://blog.naver.com/khm159/221811601286
https://stanford.edu/~shervine/l/ko/teaching/cs-230/cheatsheet-convolutional-neural-networks
등등..
'딥러닝' 카테고리의 다른 글
| FLEX .. 딥러닝 독파 시작 (2) | 2023.12.16 |
|---|---|
| Autoencoder (0) | 2023.08.05 |
| Difference of data sampling method (mini batch vs bagging model) (0) | 2023.07.12 |
| Loss function 정리(MAE, MSE, RMSE) (0) | 2023.07.12 |
| Loss function 정리 (Cross entropy, Negative log likelihood) (1) | 2023.07.10 |