
이 논문은 2개월 전에 나와서 리뷰가 많이 없었습니다. 하지만, 기존 transformer을 대체할 수 있는 논문으로 소개 되고 있어서 한번쯤 확인하시면 좋을 것 같습니다. (저도 정리할 겸 올리는거여서)
유튜브로 설명 찾아봤는데, 아직 한국분이 리뷰한 영상은 없는 것 같습니다.
인도인 분 영상 + 세미나 발표 준비겸 직관 대로 정리한 pdf파일 참고하면 될 것 같습니다.
핵심은 Long term Memory에서 test time에서도 학습이 진행되며, 정보 검색(read, write)이 어떻게 이루어지는지 설명했습니다.
4학년 학부생이 만든 pdf여서 틀릴 수도 있습니다
- Introduction
본 논문에서 기존 transformer attention 구조의 문제를 어떤 idea로 해결하는가를 다룸
- Related Work
기존 attention 관점을 -> 메모리 관점으로 변환하기 전 관련 수식에 대해 설명 함
최종적으로 Classic attention을 기준으로 설명하면, Q: 쿼리, K: 키 값의 내적으로 유사도를 산출하는 방식 (기존 transformer)
여기서 중요한 것은 메모리 관점으로 변환 될수 있다는 것. 결론적으로 수식을 보면 알 수 있듯이 Query, Key, value 값들은 전부 입력 token에서 w matrix를 곱한 것 뿐이니 최종적으로 x와 관련된 수식으로 표현이 가능
다음과 같이 설정 됨. 즉,
1) 메모리 관련 수식으로 변화 -> 메모리 관점
2) x와 관련된 수식 -> test 시점에 들어온 x를 기준으로 메모리가 업데이트 됨을 알 수 있다.
- Method
1) 장기 기억 학습 메커니즘
이 슬라이드에선 기존 attention 작동과 titans에 작동 방식을 비교하며 Long term: 장기 기억에 surprise 정보를 검색하는 아키텍처를 다루고 있음

그래서 논문에서 제안하는 Surpirse란 무엇일까?

loss로 mse를 쓰는 것을 알 수 있음. 오른쪽에 수식을 잘 설명했으니 참고 부탁
즉, t - 1 에 정보를 임베딩을 통해 도출된 t시점에 Q: (쿼리문)을 통해 검색하고, 그것을 t 시점에 value 값이랑 재구성 오류를 계산하며, 기존 알고 있지 않은 정보는 더 많은 재구성 손실을 발생하며, 이를 학습. 이 메커니즘이 장기 기억에서 Surfprise를 학습하는 방식
2) 영구 메모리 알고리즘

영구 메모리는 프롬프트와 같음. 즉 모델의 임베딩 값에 해야할 task를 명확하게 지정해주는 역할을 한다.
- How to Incorporate Memory
그렇다면 Long-term memory를 딥러닝 아키텍처에 통합하는 방법은 어떻게 할까?
3가지를 제안 함. MAC, MAG, MAL
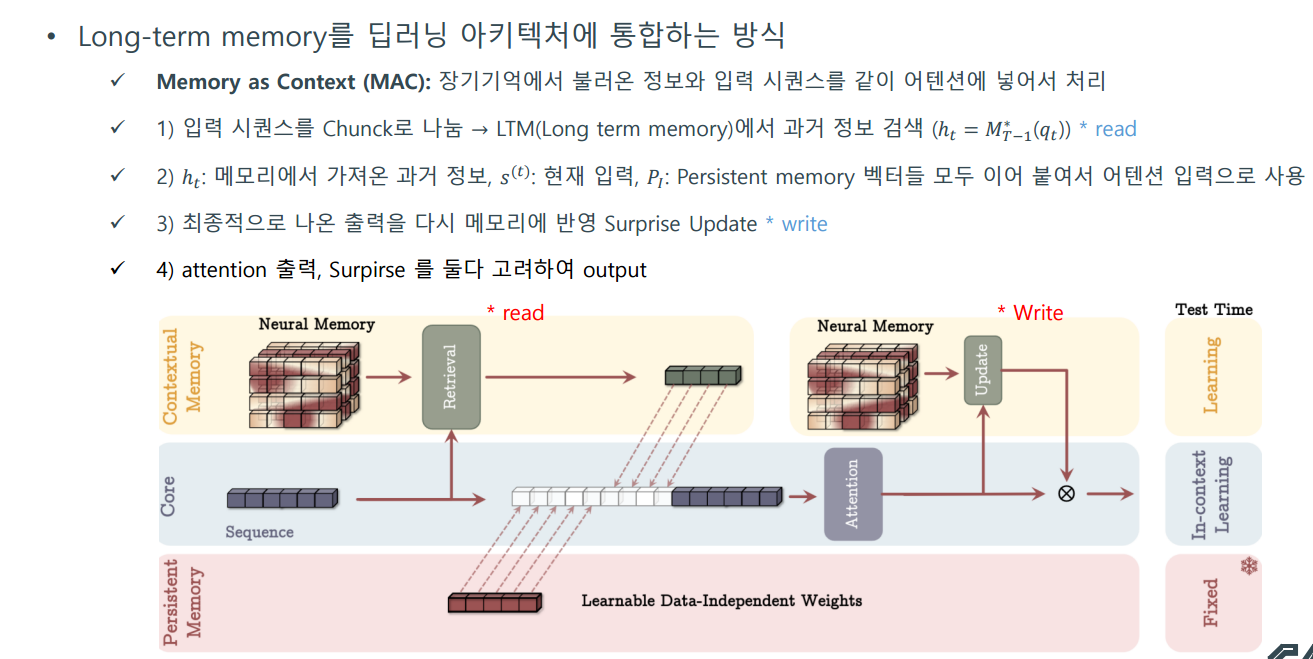
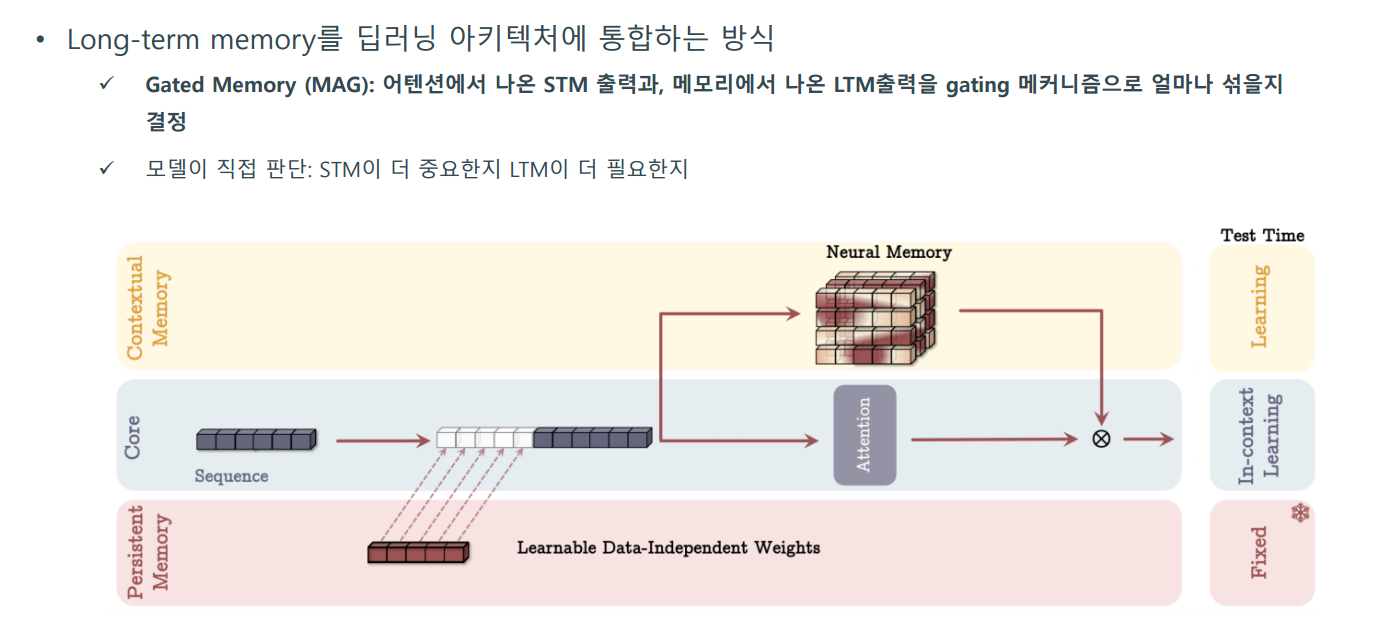
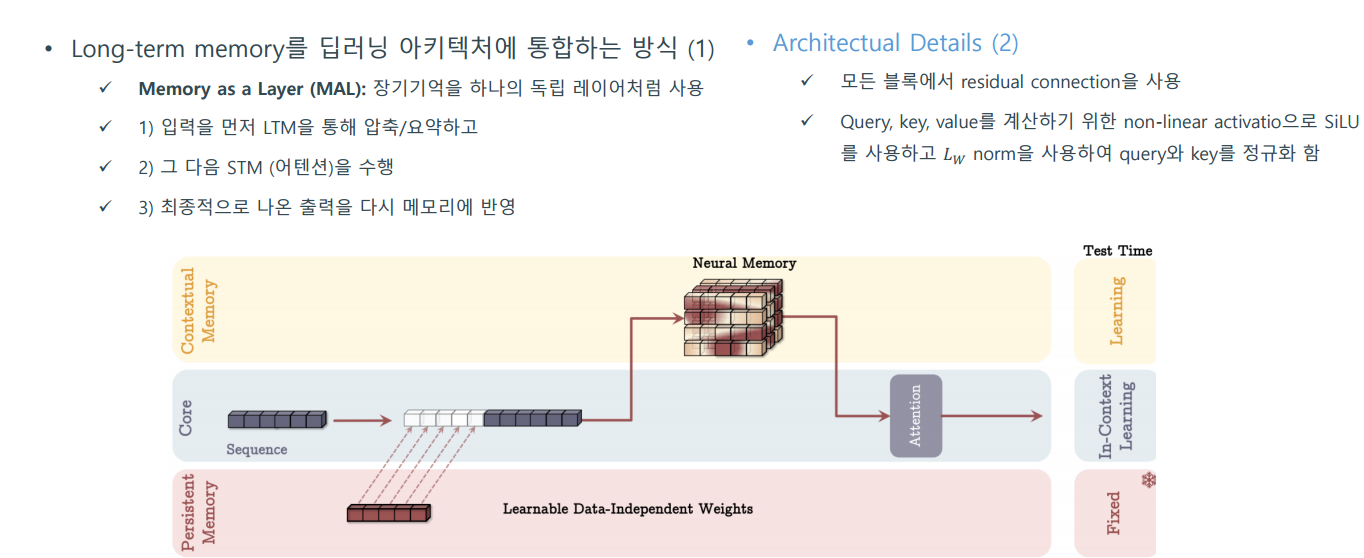
- Experiments
이건 내가쓴 pdf 참고하시길.. 귀찮. 결론은 다른 것과 비교했을때 좋아졌다 ~ 이거임
- Conclusion

일단 test time에서도 학습을 하고, 그것을 활용할 수 있다는 점이 매우 크게 다가왔음.
기존 이미지에서 사용했던 TTA 방식이 떠오르기도 함
쨌든 오늘 세미나 토론만 1시간 했는데, 앞으로도 Test data를 효율적으로 이용할 수 있는 방식들을 고안해봐야겠음
'딥러닝' 카테고리의 다른 글
| Automl (data analysis)을 위한 LLM (Multi modal에서 idea 따오기) (0) | 2025.01.08 |
|---|---|
| 이미지를 확률 분포로 생각하기 (Vae: Variational autoencoder) (2) | 2024.12.26 |
| FLEX .. 딥러닝 독파 시작 (2) | 2023.12.16 |
| Autoencoder (0) | 2023.08.05 |
| CNN(Convolutional Neural Network) (1) | 2023.07.31 |